name,summary,classifiers,description,author,author_email,description_content_type,home_page,keywords,license,maintainer,maintainer_email,package_url,platform,project_url,project_urls,release_url,requires_dist,requires_python,version,yanked,yanked_reason
datasette-auth0,Datasette plugin that authenticates users using Auth0,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-auth0
[](https://pypi.org/project/datasette-auth0/)
[](https://github.com/simonw/datasette-auth0/releases)
[](https://github.com/simonw/datasette-auth0/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-auth0/blob/main/LICENSE)
Datasette plugin that authenticates users using [Auth0](https://auth0.com/)
See [Simplest possible OAuth authentication with Auth0](https://til.simonwillison.net/auth0/oauth-with-auth0) for more about how this plugin works.
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-auth0
## Demo
You can try this out at [datasette-auth0-demo.datasette.io](https://datasette-auth0-demo.datasette.io/) - click on the top right menu icon and select ""Sign in with Auth0"".
## Initial configuration
First, create a new application in Auth0. You will need the domain, client ID and client secret for that application.
The domain should be something like `mysite.us.auth0.com`.
Add `http://127.0.0.1:8001/-/auth0-callback` to the list of Allowed Callback URLs.
Then configure these plugin secrets using `metadata.yml`:
```yaml
plugins:
datasette-auth0:
domain:
""$env"": AUTH0_DOMAIN
client_id:
""$env"": AUTH0_CLIENT_ID
client_secret:
""$env"": AUTH0_CLIENT_SECRET
```
Only the `client_secret` needs to be kept secret, but for consistency I recommend using the `$env` mechanism for all three.
In development, you can run Datasette and pass in environment variables like this:
```
AUTH0_DOMAIN=""your-domain.us.auth0.com"" \
AUTH0_CLIENT_ID=""...client-id-goes-here..."" \
AUTH0_CLIENT_SECRET=""...secret-goes-here..."" \
datasette -m metadata.yml
```
If you are deploying using `datasette publish` you can pass these using `--plugin-secret`. For example, to deploy using Cloud Run you might run the following:
```
datasette publish cloudrun mydatabase.db \
--install datasette-auth0 \
--plugin-secret datasette-auth0 domain ""your-domain.us.auth0.com"" \
--plugin-secret datasette-auth0 client_id ""your-client-id"" \
--plugin-secret datasette-auth0 client_secret ""your-client-secret"" \
--service datasette-auth0-demo
```
Once your Datasette instance is deployed, you will need to add its callback URL to the ""Allowed Callback URLs"" list in Auth0.
The callback URL should be something like:
https://url-to-your-datasette/-/auth0-callback
## Usage
Once installed, a ""Sign in with Auth0"" menu item will appear in the Datasette main menu.
You can sign in and then visit the `/-/actor` page to see full details of the `auth0` profile that has been authenticated.
You can then use [Datasette permissions](https://docs.datasette.io/en/stable/authentication.html#configuring-permissions-in-metadata-json) to grant or deny access to different parts of Datasette based on the authenticated user.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-auth0
python3 -mvenv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-auth0,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-auth0/,,https://pypi.org/project/datasette-auth0/,"{""CI"": ""https://github.com/simonw/datasette-auth0/actions"", ""Changelog"": ""https://github.com/simonw/datasette-auth0/releases"", ""Homepage"": ""https://github.com/simonw/datasette-auth0"", ""Issues"": ""https://github.com/simonw/datasette-auth0/issues""}",https://pypi.org/project/datasette-auth0/0.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""pytest-httpx ; extra == 'test'""]",>=3.7,0.1,0,
datasette-cluster-map,Datasette plugin that shows a map for any data with latitude/longitude columns,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-cluster-map
[](https://pypi.org/project/datasette-cluster-map/)
[](https://github.com/simonw/datasette-cluster-map/releases)
[](https://github.com/simonw/datasette-cluster-map/blob/main/LICENSE)
A [Datasette plugin](https://docs.datasette.io/en/stable/plugins.html) that detects tables with `latitude` and `longitude` columns and then plots them on a map using [Leaflet.markercluster](https://github.com/Leaflet/Leaflet.markercluster).
More about this project: [Datasette plugins, and building a clustered map visualization](https://simonwillison.net/2018/Apr/20/datasette-plugins/).
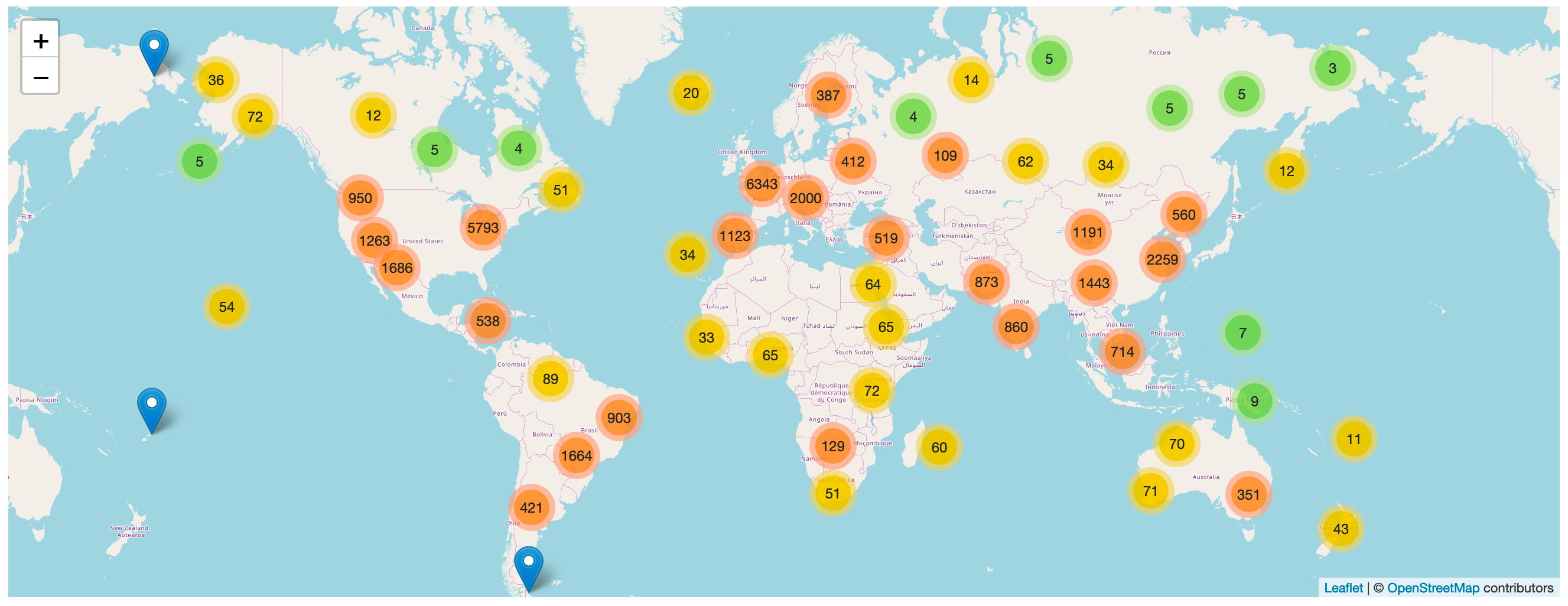
## Demo
[global-power-plants.datasettes.com](https://global-power-plants.datasettes.com/global-power-plants/global-power-plants) hosts a demo of this plugin running against a database of 33,000 power plants around the world.
## Installation
Run `datasette install datasette-cluster-map` to add this plugin to your Datasette virtual environment. Datasette will automatically load the plugin if it is installed in this way.
If you are deploying using the `datasette publish` command you can use the `--install` option:
datasette publish cloudrun mydb.db --install=datasette-cluster-map
If any of your tables have a `latitude` and `longitude` column, a map will be automatically displayed.
## Configuration
If your columns are called something else you can configure the column names using [plugin configuration](https://docs.datasette.io/en/stable/plugins.html#plugin-configuration) in a `metadata.json` file. For example, if all of your columns are called `xlat` and `xlng` you can create a `metadata.json` file like this:
```json
{
""title"": ""Regular metadata keys can go here too"",
""plugins"": {
""datasette-cluster-map"": {
""latitude_column"": ""xlat"",
""longitude_column"": ""xlng""
}
}
}
```
Then run Datasette like this:
datasette mydata.db -m metadata.json
This will configure the required column names for every database loaded by that Datasette instance.
If you want to customize the column names for just one table in one database, you can do something like this:
```json
{
""databases"": {
""polar-bears"": {
""tables"": {
""USGS_WC_eartag_deployments_2009-2011"": {
""plugins"": {
""datasette-cluster-map"": {
""latitude_column"": ""Capture Latitude"",
""longitude_column"": ""Capture Longitude""
}
}
}
}
}
}
}
```
You can also use a custom SQL query to rename those columns to `latitude` and `longitude`, [for example](https://polar-bears.now.sh/polar-bears?sql=select+*%2C%0D%0A++++%22Capture+Latitude%22+as+latitude%2C%0D%0A++++%22Capture+Longitude%22+as+longitude%0D%0Afrom+%5BUSGS_WC_eartag_deployments_2009-2011%5D):
```sql
select *,
""Capture Latitude"" as latitude,
""Capture Longitude"" as longitude
from [USGS_WC_eartag_deployments_2009-2011]
```
The map defaults to being displayed above the main results table on the page. You can use the `""container""` plugin setting to provide a CSS selector indicating an element that the map should be appended to instead.
## Custom tile layers
You can customize the tile layer used by the maps using the `tile_layer` and `tile_layer_options` configuration settings. For example, to use the [Stamen Watercolor tiles](http://maps.stamen.com/watercolor/#12/37.7706/-122.3782) you can use these settings:
```json
{
""plugins"": {
""datasette-cluster-map"": {
""tile_layer"": ""https://stamen-tiles-{s}.a.ssl.fastly.net/watercolor/{z}/{x}/{y}.{ext}"",
""tile_layer_options"": {
""attribution"": ""Map tiles by Stamen Design, CC BY 3.0 — Map data © OpenStreetMap contributors"",
""subdomains"": ""abcd"",
""minZoom"": 1,
""maxZoom"": 16,
""ext"": ""jpg""
}
}
}
}
```
The [Leaflet Providers preview list](https://leaflet-extras.github.io/leaflet-providers/preview/index.html) has details of many other tile layers you can use.
## Custom marker popups
The marker popup defaults to displaying the data for the underlying database row.
You can customize this by including a `popup` column in your results containing JSON that defines a more useful popup.
The JSON in the popup column should look something like this:
```json
{
""image"": ""https://niche-museums.imgix.net/dodgems.heic?w=800&h=400&fit=crop"",
""alt"": ""Dingles Fairground Heritage Centre"",
""title"": ""Dingles Fairground Heritage Centre"",
""description"": ""Home of the National Fairground Collection, Dingles has over 45,000 indoor square feet of vintage fairground rides... and you can go on them! Highlights include the last complete surviving and opera"",
""link"": ""/browse/museums/26""
}
```
Each of these columns is optional.
- `title` is the title to show at the top of the popup
- `image` is the URL to an image to display in the popup
- `alt` is the alt attribute to use for that image
- `description` is a longer string of text to use as a description
- `link` is a URL that the marker content should link to
You can use the SQLite `json_object()` function to construct this data dynamically as part of your SQL query. Here's an example:
```sql
select json_object(
'image', photo_url || '?w=800&h=400&fit=crop',
'title', name,
'description', substr(description, 0, 200),
'link', '/browse/museums/' || id
) as popup,
latitude, longitude from museums
where id in (26, 27) order by id
```
[Try that example here](https://www.niche-museums.com/browse?sql=select+json_object%28%0D%0A++%27image%27%2C+photo_url+%7C%7C+%27%3Fw%3D800%26h%3D400%26fit%3Dcrop%27%2C%0D%0A++%27title%27%2C+name%2C%0D%0A++%27description%27%2C+substr%28description%2C+0%2C+200%29%2C%0D%0A++%27link%27%2C+%27%2Fbrowse%2Fmuseums%2F%27+%7C%7C+id%0D%0A++%29+as+popup%2C%0D%0A++latitude%2C+longitude+from+museums) or take a look at [this demo built using a SQL view](https://dogsheep-photos.dogsheep.net/public/photos_on_a_map).
## How I deployed the demo
datasette publish cloudrun global-power-plants.db \
--service global-power-plants \
--metadata metadata.json \
--install=datasette-cluster-map \
--extra-options=""--config facet_time_limit_ms:1000""
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-cluster-map
python3 -mvenv venv
source venv/bin/activate
Or if you are using `pipenv`:
pipenv shell
Now install the dependencies and tests:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-cluster-map,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-cluster-map/,,https://pypi.org/project/datasette-cluster-map/,"{""CI"": ""https://github.com/simonw/datasette-cluster-map/actions"", ""Changelog"": ""https://github.com/simonw/datasette-cluster-map/releases"", ""Homepage"": ""https://github.com/simonw/datasette-cluster-map"", ""Issues"": ""https://github.com/simonw/datasette-cluster-map/issues""}",https://pypi.org/project/datasette-cluster-map/0.17.2/,"[""datasette (>=0.54)"", ""datasette-leaflet (>=0.2.2)"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""httpx ; extra == 'test'"", ""sqlite-utils ; extra == 'test'""]",,0.17.2,0,
datasette-copy-to-memory,Copy database files into an in-memory database on startup,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-copy-to-memory
[](https://pypi.org/project/datasette-copy-to-memory/)
[](https://github.com/simonw/datasette-copy-to-memory/releases)
[](https://github.com/simonw/datasette-copy-to-memory/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-copy-to-memory/blob/main/LICENSE)
Copy database files into an in-memory database on startup
This plugin is **highly experimental**. It currently exists to support Datasette performance research, and is not designed for actual production usage.
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-copy-to-memory
## Usage
On startup, Datasette will create an in-memory named database for each attached database. This database will have the same name but with `_memory` at the end.
So running this:
datasette fixtures.db
Will serve two databases: the original at `/fixtures` and the in-memory copy at `/fixtures_memory`.
## Demo
A demo is running on [latest-with-plugins.datasette.io](https://latest-with-plugins.datasette.io/) - the [/fixtures_memory](https://latest-with-plugins.datasette.io/fixtures_memory) table there is provided by this plugin.
## Configuration
By default every attached database file will be loaded into a `_memory` copy.
You can use plugin configuration to specify just a subset of the database. For example, to create `github_memory` but not `fixtures_memory` you would use the following `metadata.yml` file:
```yaml
plugins:
datasette-copy-to-memory:
databases:
- github
```
Then start Datasette like this:
datasette github.db fixtures.db -m metadata.yml
If you don't want to have a `fixtures` and `fixtures_memory` database, you can use `replace: true` to have the plugin replace the file-backed database with the new in-memory one, reusing the same database name:
```yaml
plugins:
datasette-copy-to-memory:
replace: true
```
Then:
datasette github.db fixtures.db -m metadata.yml
This will result in both `/github` and `/fixtures` but no `/github_memory` or `/fixtures_memory`.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-copy-to-memory
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-copy-to-memory,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-copy-to-memory/,,https://pypi.org/project/datasette-copy-to-memory/,"{""CI"": ""https://github.com/simonw/datasette-copy-to-memory/actions"", ""Changelog"": ""https://github.com/simonw/datasette-copy-to-memory/releases"", ""Homepage"": ""https://github.com/simonw/datasette-copy-to-memory"", ""Issues"": ""https://github.com/simonw/datasette-copy-to-memory/issues""}",https://pypi.org/project/datasette-copy-to-memory/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""sqlite-utils ; extra == 'test'""]",>=3.7,0.2,0,
datasette-expose-env,Datasette plugin to expose selected environment variables at /-/env for debugging,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-expose-env
[](https://pypi.org/project/datasette-expose-env/)
[](https://github.com/simonw/datasette-expose-env/releases)
[](https://github.com/simonw/datasette-expose-env/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-expose-env/blob/main/LICENSE)
Datasette plugin to expose selected environment variables at `/-/env` for debugging
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-expose-env
## Configuration
Decide on a list of environment variables you would like to expose, then add the following to your `metadata.yml` configuration:
```yaml
plugins:
datasette-expose-env:
- ENV_VAR_1
- ENV_VAR_2
- ENV_VAR_3
```
If you are using JSON in a `metadata.json` file use the following:
```json
{
""plugins"": {
""datasette-expose-env"": [
""ENV_VAR_1"",
""ENV_VAR_2"",
""ENV_VAR_3""
]
}
}
```
Visit `/-/env` on your Datasette instance to see the values of the environment variables.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-expose-env
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-expose-env,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-expose-env/,,https://pypi.org/project/datasette-expose-env/,"{""CI"": ""https://github.com/simonw/datasette-expose-env/actions"", ""Changelog"": ""https://github.com/simonw/datasette-expose-env/releases"", ""Homepage"": ""https://github.com/simonw/datasette-expose-env"", ""Issues"": ""https://github.com/simonw/datasette-expose-env/issues""}",https://pypi.org/project/datasette-expose-env/0.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.1,0,
datasette-external-links-new-tabs,Datasette plugin to open external links in new tabs,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-external-links-new-tabs
[](https://pypi.org/project/datasette-external-links-new-tabs/)
[](https://github.com/ocdtrekkie/datasette-external-links-new-tabs/releases)
[](https://github.com/ocdtrekkie/datasette-external-links-new-tabs/actions?query=workflow%3ATest)
[](https://github.com/ocdtrekkie/datasette-external-links-new-tabs/blob/main/LICENSE)
Datasette plugin to open external links in new tabs
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-external-links-new-tabs
## Usage
There are no usage instructions, it simply opens external links in a new tab.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-external-links-new-tabs
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Jacob Weisz,,text/markdown,https://github.com/ocdtrekkie/datasette-external-links-new-tabs,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-external-links-new-tabs/,,https://pypi.org/project/datasette-external-links-new-tabs/,"{""CI"": ""https://github.com/ocdtrekkie/datasette-external-links-new-tabs/actions"", ""Changelog"": ""https://github.com/ocdtrekkie/datasette-external-links-new-tabs/releases"", ""Homepage"": ""https://github.com/ocdtrekkie/datasette-external-links-new-tabs"", ""Issues"": ""https://github.com/ocdtrekkie/datasette-external-links-new-tabs/issues""}",https://pypi.org/project/datasette-external-links-new-tabs/0.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.1,0,
datasette-gunicorn,Run a Datasette server using Gunicorn,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-gunicorn
[](https://pypi.org/project/datasette-gunicorn/)
[](https://github.com/simonw/datasette-gunicorn/releases)
[](https://github.com/simonw/datasette-gunicorn/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-gunicorn/blob/main/LICENSE)
Run a [Datasette](https://datasette.io/) server using [Gunicorn](https://gunicorn.org/)
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-gunicorn
## Usage
The plugin adds a new `datasette gunicorn` command. This takes most of the same options as `datasette serve`, plus one more option for setting the number of Gunicorn workers to start:
`-w/--workers X` - set the number of workers. Defaults to 1.
To start serving a database using 4 workers, run the following:
datasette gunicorn fixtures.db -w 4
It is advisable to switch your datasette [into WAL mode](https://til.simonwillison.net/sqlite/enabling-wal-mode) to get the best performance out of this configuration:
sqlite3 fixtures.db 'PRAGMA journal_mode=WAL;'
Run `datasette gunicorn --help` for a full list of options (which are the same as `datasette serve --help`, with the addition of the new `-w` option).
## datasette gunicorn --help
Not all of the options to `datasette serve` are supported. Here's the full list of available options:
```
Usage: datasette gunicorn [OPTIONS] [FILES]...
Start a Gunicorn server running to serve Datasette
Options:
-i, --immutable PATH Database files to open in immutable mode
-h, --host TEXT Host for server. Defaults to 127.0.0.1 which means
only connections from the local machine will be
allowed. Use 0.0.0.0 to listen to all IPs and allow
access from other machines.
-p, --port INTEGER RANGE Port for server, defaults to 8001. Use -p 0 to
automatically assign an available port.
[0<=x<=65535]
--cors Enable CORS by serving Access-Control-Allow-Origin:
*
--load-extension TEXT Path to a SQLite extension to load
--inspect-file TEXT Path to JSON file created using ""datasette inspect""
-m, --metadata FILENAME Path to JSON/YAML file containing license/source
metadata
--template-dir DIRECTORY Path to directory containing custom templates
--plugins-dir DIRECTORY Path to directory containing custom plugins
--static MOUNT:DIRECTORY Serve static files from this directory at /MOUNT/...
--memory Make /_memory database available
--config CONFIG Deprecated: set config option using
configname:value. Use --setting instead.
--setting SETTING... Setting, see
docs.datasette.io/en/stable/settings.html
--secret TEXT Secret used for signing secure values, such as
signed cookies
--version-note TEXT Additional note to show on /-/versions
--help-settings Show available settings
--create Create database files if they do not exist
--crossdb Enable cross-database joins using the /_memory
database
--nolock Ignore locking, open locked files in read-only mode
-w, --workers INTEGER Number of Gunicorn workers [default: 1]
--help Show this message and exit.
```
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-gunicorn
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-gunicorn,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-gunicorn/,,https://pypi.org/project/datasette-gunicorn/,"{""CI"": ""https://github.com/simonw/datasette-gunicorn/actions"", ""Changelog"": ""https://github.com/simonw/datasette-gunicorn/releases"", ""Homepage"": ""https://github.com/simonw/datasette-gunicorn"", ""Issues"": ""https://github.com/simonw/datasette-gunicorn/issues""}",https://pypi.org/project/datasette-gunicorn/0.1/,"[""datasette"", ""gunicorn"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""cogapp ; extra == 'test'""]",>=3.7,0.1,0,
datasette-gzip,Add gzip compression to Datasette,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-gzip
[](https://pypi.org/project/datasette-gzip/)
[](https://github.com/simonw/datasette-gzip/releases)
[](https://github.com/simonw/datasette-gzip/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-gzip/blob/main/LICENSE)
Add gzip compression to Datasette
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-gzip
## Usage
Once installed, Datasette will obey the `Accept-Encoding:` header sent by browsers or other user agents and return content compressed in the most appropriate way.
This plugin is a thin wrapper for the [asgi-gzip library](https://github.com/simonw/asgi-gzip), which extracts the [GzipMiddleware](https://www.starlette.io/middleware/#gzipmiddleware) from Starlette.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-gzip
python3 -mvenv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-gzip,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-gzip/,,https://pypi.org/project/datasette-gzip/,"{""CI"": ""https://github.com/simonw/datasette-gzip/actions"", ""Changelog"": ""https://github.com/simonw/datasette-gzip/releases"", ""Homepage"": ""https://github.com/simonw/datasette-gzip"", ""Issues"": ""https://github.com/simonw/datasette-gzip/issues""}",https://pypi.org/project/datasette-gzip/0.2/,"[""datasette"", ""asgi-gzip"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.2,0,
datasette-hashed-urls,Optimize Datasette performance behind a caching proxy,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-hashed-urls
[](https://pypi.org/project/datasette-hashed-urls/)
[](https://github.com/simonw/datasette-hashed-urls/releases)
[](https://github.com/simonw/datasette-hashed-urls/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-hashed-urls/blob/main/LICENSE)
Optimize Datasette performance behind a caching proxy
When you open a database file in immutable mode using the `-i` option, Datasette calculates a SHA-256 hash of the contents of that file on startup.
This content hash can then optionally be used to create URLs that are guaranteed to change if the contents of the file changes in the future.
The result is pages that can be cached indefinitely by both browsers and caching proxies - providing a significant performance boost.
## Demo
A demo of this plugin is running at https://datasette-hashed-urls.vercel.app/
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-hashed-urls
## Usage
Once installed, this plugin will act on any immutable database files that are loaded into Datasette:
datasette -i fixtures.db
The database will automatically be renamed to incorporate a hash of the contents of the SQLite file - so the above database would be served as:
http://127.0.0.1:8001/fixtures-aa7318b
Every page that accesss that database, including JSON endpoints, will be served with the following far-future cache expiry header:
cache-control: max-age=31536000, public
Here `max-age=31536000` is the number of seconds in a year.
A caching proxy such as Cloudflare can then be used to cache and accelerate content served by Datasette.
When the database file is updated and the server is restarted, the hash will change and content will be served from a new URL. Any hits to the previous hashed URLs will be automatically redirected.
If you run Datasette using the `--crossdb` option to enable [cross-database queries](https://docs.datasette.io/en/stable/sql_queries.html#cross-database-queries) the `_memory` database will also have a hash added to its URL - in this case, the hash will be a combination of the hashes of the other attached databases.
## Configuration
You can use the `max_age` plugin configuration setting to change the cache duration specified in the `cache-control` HTTP header.
To set the cache expiry time to one hour you would add this to your Datasette `metadata.json` configuration file:
```json
{
""plugins"": {
""datasette-hashed-urls"": {
""max_age"": 3600
}
}
}
```
## History
This functionality used to ship as part of Datasette itself, as a feature called [Hashed URL mode](https://docs.datasette.io/en/0.60.2/performance.html#hashed-url-mode).
That feature has been deprecated and will be removed in Datasette 1.0. This plugin should be used as an alternative.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-hashed-urls
python3 -mvenv venv
source venv/bin/activate
Or if you are using `pipenv`:
pipenv shell
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-hashed-urls,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-hashed-urls/,,https://pypi.org/project/datasette-hashed-urls/,"{""CI"": ""https://github.com/simonw/datasette-hashed-urls/actions"", ""Changelog"": ""https://github.com/simonw/datasette-hashed-urls/releases"", ""Homepage"": ""https://github.com/simonw/datasette-hashed-urls"", ""Issues"": ""https://github.com/simonw/datasette-hashed-urls/issues""}",https://pypi.org/project/datasette-hashed-urls/0.4/,"[""datasette (>=0.61.1)"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""sqlite-utils ; extra == 'test'""]",>=3.7,0.4,0,
datasette-hovercards,Add preview hovercards to links in Datasette,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-hovercards
[](https://pypi.org/project/datasette-hovercards/)
[](https://github.com/simonw/datasette-hovercards/releases)
[](https://github.com/simonw/datasette-hovercards/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-hovercards/blob/main/LICENSE)
Add preview hovercards to links in Datasette
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-hovercards
## Usage
Once installed, hovering over a link to a row within the Datasette interface - for example a foreign key reference on the table page - should show a hovercard with a preview of that row.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-hovercards
python3 -mvenv venv
source venv/bin/activate
Or if you are using `pipenv`:
pipenv shell
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-hovercards,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-hovercards/,,https://pypi.org/project/datasette-hovercards/,"{""CI"": ""https://github.com/simonw/datasette-hovercards/actions"", ""Changelog"": ""https://github.com/simonw/datasette-hovercards/releases"", ""Homepage"": ""https://github.com/simonw/datasette-hovercards"", ""Issues"": ""https://github.com/simonw/datasette-hovercards/issues""}",https://pypi.org/project/datasette-hovercards/0.1a0/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.6,0.1a0,0,
datasette-ics,Datasette plugin for outputting iCalendar files,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-ics
[](https://pypi.org/project/datasette-ics/)
[](https://github.com/simonw/datasette-ics/releases)
[](https://github.com/simonw/datasette-ics/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-ics/blob/main/LICENSE)
Datasette plugin that adds support for generating [iCalendar .ics files](https://tools.ietf.org/html/rfc5545) with the results of a SQL query.
## Installation
Install this plugin in the same environment as Datasette to enable the `.ics` output extension.
$ pip install datasette-ics
## Usage
To create an iCalendar file you need to define a custom SQL query that returns a required set of columns:
* `event_name` - the short name for the event
* `event_dtstart` - when the event starts
The following columns are optional:
* `event_dtend` - when the event ends
* `event_duration` - the duration of the event (use instead of `dtend`)
* `event_description` - a longer description of the event
* `event_uid` - a globally unique identifier for this event
* `event_tzid` - the timezone for the event, e.g. `America/Chicago`
A query that returns these columns can then be returned as an ics feed by adding the `.ics` extension.
## Demo
[This SQL query]([https://www.rockybeaches.com/data?sql=with+inner+as+(%0D%0A++select%0D%0A++++datetime%2C%0D%0A++++substr(datetime%2C+0%2C+11)+as+date%2C%0D%0A++++mllw_feet%2C%0D%0A++++lag(mllw_feet)+over+win+as+previous_mllw_feet%2C%0D%0A++++lead(mllw_feet)+over+win+as+next_mllw_feet%0D%0A++from%0D%0A++++tide_predictions%0D%0A++where%0D%0A++++station_id+%3D+%3Astation_id%0D%0A++++and+datetime+%3E%3D+date()%0D%0A++++window+win+as+(%0D%0A++++++order+by%0D%0A++++++++datetime%0D%0A++++)%0D%0A++order+by%0D%0A++++datetime%0D%0A)%2C%0D%0Alowest_tide_per_day+as+(%0D%0A++select%0D%0A++++date%2C%0D%0A++++datetime%2C%0D%0A++++mllw_feet%0D%0A++from%0D%0A++++inner%0D%0A++where%0D%0A++++mllw_feet+%3C%3D+previous_mllw_feet%0D%0A++++and+mllw_feet+%3C%3D+next_mllw_feet%0D%0A)%0D%0Aselect%0D%0A++min(datetime)+as+event_dtstart%2C%0D%0A++%27Low+tide%3A+%27+||+mllw_feet+||+%27+feet%27+as+event_name%2C%0D%0A++%27America%2FLos_Angeles%27+as+event_tzid%0D%0Afrom%0D%0A++lowest_tide_per_day%0D%0Agroup+by%0D%0A++date%0D%0Aorder+by%0D%0A++date&station_id=9414131) calculates the lowest tide per day at Pillar Point in Half Moon Bay, California.
Since the query returns `event_name`, `event_dtstart` and `event_tzid` columns it produces [this ICS feed](https://www.rockybeaches.com/data.ics?sql=with+inner+as+(%0D%0A++select%0D%0A++++datetime%2C%0D%0A++++substr(datetime%2C+0%2C+11)+as+date%2C%0D%0A++++mllw_feet%2C%0D%0A++++lag(mllw_feet)+over+win+as+previous_mllw_feet%2C%0D%0A++++lead(mllw_feet)+over+win+as+next_mllw_feet%0D%0A++from%0D%0A++++tide_predictions%0D%0A++where%0D%0A++++station_id+%3D+%3Astation_id%0D%0A++++and+datetime+%3E%3D+date()%0D%0A++++window+win+as+(%0D%0A++++++order+by%0D%0A++++++++datetime%0D%0A++++)%0D%0A++order+by%0D%0A++++datetime%0D%0A)%2C%0D%0Alowest_tide_per_day+as+(%0D%0A++select%0D%0A++++date%2C%0D%0A++++datetime%2C%0D%0A++++mllw_feet%0D%0A++from%0D%0A++++inner%0D%0A++where%0D%0A++++mllw_feet+%3C%3D+previous_mllw_feet%0D%0A++++and+mllw_feet+%3C%3D+next_mllw_feet%0D%0A)%0D%0Aselect%0D%0A++min(datetime)+as+event_dtstart%2C%0D%0A++%27Low+tide%3A+%27+||+mllw_feet+||+%27+feet%27+as+event_name%2C%0D%0A++%27America%2FLos_Angeles%27+as+event_tzid%0D%0Afrom%0D%0A++lowest_tide_per_day%0D%0Agroup+by%0D%0A++date%0D%0Aorder+by%0D%0A++date&station_id=9414131). If you subscribe to that in a calendar application such as Apple Calendar you get something that looks like this:

## Using a canned query
Datasette's [canned query mechanism](https://datasette.readthedocs.io/en/stable/sql_queries.html#canned-queries) can be used to configure calendars. If a canned query definition has a `title` that will be used as the title of the calendar.
Here's an example, defined using a `metadata.yaml` file:
```yaml
databases:
mydatabase:
queries:
calendar:
title: My Calendar
sql: |-
select
title as event_name,
start as event_dtstart,
description as event_description
from
events
order by
start
limit
100
```
This will result in a calendar feed at `http://localhost:8001/mydatabase/calendar.ics`
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-ics,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-ics/,,https://pypi.org/project/datasette-ics/,"{""CI"": ""https://github.com/simonw/datasette-ics/actions"", ""Changelog"": ""https://github.com/simonw/datasette-ics/releases"", ""Homepage"": ""https://github.com/simonw/datasette-ics"", ""Issues"": ""https://github.com/simonw/datasette-ics/issues""}",https://pypi.org/project/datasette-ics/0.5.2/,"[""datasette (>=0.49)"", ""ics (==0.7.2)"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",,0.5.2,0,
datasette-mp3-audio,Turn .mp3 URLs into an audio player in the Datasette interface,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-mp3-audio
[](https://pypi.org/project/datasette-mp3-audio/)
[](https://github.com/simonw/datasette-mp3-audio/releases)
[](https://github.com/simonw/datasette-mp3-audio/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-mp3-audio/blob/main/LICENSE)
Turn .mp3 URLs into an audio player in the Datasette interface
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-mp3-audio
## Demo
Try this plugin at [https://scotrail.datasette.io/scotrail/announcements](https://scotrail.datasette.io/scotrail/announcements)
The demo uses ScotRail train announcements from [matteason/scotrail-announcements-june-2022](https://github.com/matteason/scotrail-announcements-june-2022).
## Usage
Once installed, any cells with a value that ends in `.mp3` and starts with either `http://` or `/` or `https://` will be turned into an embedded HTML audio element like this:
```html
```
A ""Play X MP3s on this page"" button will be added to athe top of any table page listing more than one MP3.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-mp3-audio
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-mp3-audio,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-mp3-audio/,,https://pypi.org/project/datasette-mp3-audio/,"{""CI"": ""https://github.com/simonw/datasette-mp3-audio/actions"", ""Changelog"": ""https://github.com/simonw/datasette-mp3-audio/releases"", ""Homepage"": ""https://github.com/simonw/datasette-mp3-audio"", ""Issues"": ""https://github.com/simonw/datasette-mp3-audio/issues""}",https://pypi.org/project/datasette-mp3-audio/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""sqlite-utils ; extra == 'test'""]",>=3.7,0.2,0,
datasette-multiline-links,Make multiple newline separated URLs clickable in Datasette,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-multiline-links
[](https://pypi.org/project/datasette-multiline-links/)
[](https://github.com/simonw/datasette-multiline-links/releases)
[](https://github.com/simonw/datasette-multiline-links/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-multiline-links/blob/main/LICENSE)
Make multiple newline separated URLs clickable in Datasette
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-multiline-links
## Usage
Once installed, if a cell has contents like this:
```
https://example.com
Not a link
https://google.com
```
It will be rendered as:
```html
https://example.com
Not a link
https://google.com
```
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-multiline-links
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-multiline-links,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-multiline-links/,,https://pypi.org/project/datasette-multiline-links/,"{""CI"": ""https://github.com/simonw/datasette-multiline-links/actions"", ""Changelog"": ""https://github.com/simonw/datasette-multiline-links/releases"", ""Homepage"": ""https://github.com/simonw/datasette-multiline-links"", ""Issues"": ""https://github.com/simonw/datasette-multiline-links/issues""}",https://pypi.org/project/datasette-multiline-links/0.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.1,0,
datasette-nteract-data-explorer,automatic visual data explorer for datasette,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-nteract-data-explorer
[](https://pypi.org/project/datasette-nteract-data-explorer/)
[](https://github.com/hydrosquall/datasette-nteract-data-explorer/releases)
[](https://github.com/hydrosquall/datasette-nteract-data-explorer/actions?query=workflow%3ATest)
[](https://github.com/hydrosquall/datasette-nteract-data-explorer/blob/main/LICENSE)
An automatic data visualization plugin for the [Datasette](https://datasette.io/) ecosystem. See your dataset from multiple views with an easy-to-use, customizable menu-based interface.
## Demo
Try the [live demo](https://datasette-nteract-data-explorer.vercel.app/happy_planet_index/hpi_cleaned?_size=137)

_Running Datasette with the Happy Planet Index dataset_
## Installation
Install this plugin in the same Python environment as Datasette.
```bash
datasette install datasette-nteract-data-explorer
```
## Usage
- Click ""View in Data Explorer"" to expand the visualization panel
- Click the icons on the right side to change the visualization type.
- Use the menus underneath the graphing area to configure your graph (e.g. change which columns to graph, colors to use, etc)
- Use ""advanced settings"" mode to override the inferred column types. For example, you may want to treat a number as a ""string"" to be able to use it as a category.
- See a [live demo](https://data-explorer.nteract.io/) of the original Nteract data-explorer component used in isolation.
You can run a minimal demo after the installation step
```bash
datasette -i demo/happy_planet_index.db
```
If you're interested in improving the demo site, you can run a copy of the site the extra metadata/plugins used in the [published demo](https://datasette-nteract-data-explorer.vercel.app).
```bash
make run-demo
```
Thank you for reading this far! If you use the Data Explorer in your own site and would like others to find it, you can [mention it here](https://github.com/hydrosquall/datasette-nteract-data-explorer/discussions/10).
## Development
See [contributing docs](./docs/CONTRIBUTING.md).
## Acknowledgements
- The [Data Explorer](https://github.com/nteract/data-explorer) was designed by Elijah Meeks. I co-maintain this project as part of the [Nteract](https://nteract.io/) open-source team. You can read about the design behind this tool [here](https://blog.nteract.io/designing-the-nteract-data-explorer-f4476d53f897)
- The data model is based on the [Frictionless Data Spec](https://specs.frictionlessdata.io/).
- This plugin was bootstrapped by Simon Willison's [Datasette plugin template](https://simonwillison.net/2020/Jun/20/cookiecutter-plugins/)
- Demo dataset from the [Happy Planet Index](https://happyplanetindex.org/) was cleaned by Doris Lee. This dataset was chosen because of its global appeal, modest size, and variety in column datatypes (numbers, low cardinality and high cardinality strings, booleans).
- Hosting for the demo site is provided by Vercel.
[](https://vercel.com/?utm_source=datasette-visualization-plugin-demos&utm_campaign=oss)
",Cameron Yick,,text/markdown,https://github.com/hydrosquall/datasette-nteract-data-explorer,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-nteract-data-explorer/,,https://pypi.org/project/datasette-nteract-data-explorer/,"{""CI"": ""https://github.com/hydrosquall/datasette-nteract-data-explorer/actions"", ""Changelog"": ""https://github.com/hydrosquall/datasette-nteract-data-explorer/releases"", ""Homepage"": ""https://github.com/hydrosquall/datasette-nteract-data-explorer"", ""Issues"": ""https://github.com/hydrosquall/datasette-nteract-data-explorer/issues""}",https://pypi.org/project/datasette-nteract-data-explorer/0.5.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.5.1,0,
datasette-packages,Show a list of currently installed Python packages,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-packages
[](https://pypi.org/project/datasette-packages/)
[](https://github.com/simonw/datasette-packages/releases)
[](https://github.com/simonw/datasette-packages/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-packages/blob/main/LICENSE)
Show a list of currently installed Python packages
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-packages
## Usage
Visit `/-/packages` to see a list of installed Python packages.
Visit `/-/packages.json` to get that back as JSON.
## Demo
The output of this plugin can be seen here:
- https://latest-with-plugins.datasette.io/-/packages
- https://latest-with-plugins.datasette.io/-/packages.json
## With datasette-graphql
if you have version 2.1 or higher of the [datasette-graphql](https://datasette.io/plugins/datasette-graphql) plugin installed you can also query the list of packages using this GraphQL query:
```graphql
{
packages {
name
version
}
}
```
[Demo of this query](https://latest-with-plugins.datasette.io/graphql?query=%7B%0A%20%20%20%20packages%20%7B%0A%20%20%20%20%20%20%20%20name%0A%20%20%20%20%20%20%20%20version%0A%20%20%20%20%7D%0A%7D).
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-packages
python3 -mvenv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-packages,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-packages/,,https://pypi.org/project/datasette-packages/,"{""CI"": ""https://github.com/simonw/datasette-packages/actions"", ""Changelog"": ""https://github.com/simonw/datasette-packages/releases"", ""Homepage"": ""https://github.com/simonw/datasette-packages"", ""Issues"": ""https://github.com/simonw/datasette-packages/issues""}",https://pypi.org/project/datasette-packages/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""datasette-graphql (>=2.1) ; extra == 'test'""]",>=3.7,0.2,0,
datasette-pretty-traces,Prettier formatting for ?_trace=1 traces,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-pretty-traces
[](https://pypi.org/project/datasette-pretty-traces/)
[](https://github.com/simonw/datasette-pretty-traces/releases)
[](https://github.com/simonw/datasette-pretty-traces/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-pretty-traces/blob/main/LICENSE)
Prettier formatting for `?_trace=1` traces
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-pretty-traces
## Usage
Once installed, run Datasette using `--setting trace_debug 1`:
datasette fixtures.db --setting trace_debug 1
Then navigate to any page and add `?_trace=` to the URL:
http://localhost:8001/?_trace=1
The plugin will scroll you down the page to the visualized trace information.
## Demo
You can try out the demo here:
- [/?_trace=1](https://latest-with-plugins.datasette.io/?_trace=1) tracing the homepage
- [/github/commits?_trace=1](https://latest-with-plugins.datasette.io/github/commits?_trace=1) tracing a table page
## Screenshot

## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-pretty-traces
python3 -mvenv venv
source venv/bin/activate
Or if you are using `pipenv`:
pipenv shell
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-pretty-traces,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-pretty-traces/,,https://pypi.org/project/datasette-pretty-traces/,"{""CI"": ""https://github.com/simonw/datasette-pretty-traces/actions"", ""Changelog"": ""https://github.com/simonw/datasette-pretty-traces/releases"", ""Homepage"": ""https://github.com/simonw/datasette-pretty-traces"", ""Issues"": ""https://github.com/simonw/datasette-pretty-traces/issues""}",https://pypi.org/project/datasette-pretty-traces/0.4/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.6,0.4,0,
datasette-public,Make specific Datasette tables visible to the public,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-public
[](https://pypi.org/project/datasette-public/)
[](https://github.com/simonw/datasette-public/releases)
[](https://github.com/simonw/datasette-public/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-public/blob/main/LICENSE)
Make specific Datasette tables visible to the public
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-public
## Usage
Any tables listed in the `_public_tables` table will be visible to the public, even if the rest of the Datasette instance does not allow anonymous access.
The root user (and any user with the new `public-tables` permission) will get a new option in the table action menu allowing them to toggle a table between public and private.
Installing this plugin also causes `allow-sql` permission checks to fall back to checking if the user has access to the entire database. This is to avoid users with access to a single public table being able to access data from other tables using the `?_where=` query string parameter.
## Configuration
This plugin creates a new table in one of your databases called `_public_tables`.
This table defaults to being created in the first database passed to Datasette.
To create it in a different named database, use this plugin configuration:
```json
{
""plugins"": {
""datasette-public"": {
""database"": ""database_to_create_table_in""
}
}
}
```
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-public
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-public,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-public/,,https://pypi.org/project/datasette-public/,"{""CI"": ""https://github.com/simonw/datasette-public/actions"", ""Changelog"": ""https://github.com/simonw/datasette-public/releases"", ""Homepage"": ""https://github.com/simonw/datasette-public"", ""Issues"": ""https://github.com/simonw/datasette-public/issues""}",https://pypi.org/project/datasette-public/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.2,0,
datasette-query-files,Write Datasette canned queries as plain SQL files,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-query-files
[](https://pypi.org/project/datasette-query-files/)
[](https://github.com/eyeseast/datasette-query-files/releases)
[](https://github.com/eyeseast/datasette-query-files/actions?query=workflow%3ATest)
[](https://github.com/eyeseast/datasette-query-files/blob/main/LICENSE)
Write Datasette canned queries as plain SQL files.
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-query-files
Or using `pip` or `pipenv`:
pip install datasette-query-files
pipenv install datasette-query-files
## Usage
This plugin will look for [canned queries](https://docs.datasette.io/en/stable/sql_queries.html#canned-queries) in the filesystem, in addition any defined in metadata.
Let's say you're working in a directory called `project-directory`, with a database file called `my-project.db`. Start by creating a `queries` directory with a `my-project` directory inside it. Any SQL file inside that `my-project` folder will become a canned query that can be run on the `my-project` database. If you have a `query-name.sql` file and a `query-name.json` (or `query-name.yml`) file in the same directory, the JSON file will be used as query metadata.
```
project-directory/
my-project.db
queries/
my-project/
query-name.sql # a query
query-name.yml # query metadata
```
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-query-files
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Chris Amico,,text/markdown,https://github.com/eyeseast/datasette-query-files,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-query-files/,,https://pypi.org/project/datasette-query-files/,"{""CI"": ""https://github.com/eyeseast/datasette-query-files/actions"", ""Changelog"": ""https://github.com/eyeseast/datasette-query-files/releases"", ""Homepage"": ""https://github.com/eyeseast/datasette-query-files"", ""Issues"": ""https://github.com/eyeseast/datasette-query-files/issues""}",https://pypi.org/project/datasette-query-files/0.1.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.1.1,0,
datasette-redirect-forbidden,Redirect forbidden requests to a login page,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-redirect-forbidden
[](https://pypi.org/project/datasette-redirect-forbidden/)
[](https://github.com/simonw/datasette-redirect-forbidden/releases)
[](https://github.com/simonw/datasette-redirect-forbidden/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-redirect-forbidden/blob/main/LICENSE)
Redirect forbidden requests to a login page
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-redirect-forbidden
## Usage
Add the following to your `metadata.yml` (or `metadata.json`) file to configure the plugin:
```yaml
plugins:
datasette-redirect-forbidden:
redirect_to: /-/login
```
Any 403 forbidden pages will redirect to the specified page.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-redirect-forbidden
python3 -mvenv venv
source venv/bin/activate
Or if you are using `pipenv`:
pipenv shell
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-redirect-forbidden,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-redirect-forbidden/,,https://pypi.org/project/datasette-redirect-forbidden/,"{""CI"": ""https://github.com/simonw/datasette-redirect-forbidden/actions"", ""Changelog"": ""https://github.com/simonw/datasette-redirect-forbidden/releases"", ""Homepage"": ""https://github.com/simonw/datasette-redirect-forbidden"", ""Issues"": ""https://github.com/simonw/datasette-redirect-forbidden/issues""}",https://pypi.org/project/datasette-redirect-forbidden/0.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.6,0.1,0,
datasette-render-image-tags,Turn any URLs ending in .jpg/.png/.gif into img tags with width 200,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-render-image-tags
[](https://pypi.org/project/datasette-render-image-tags/)
[](https://github.com/simonw/datasette-render-image-tags/releases)
[](https://github.com/simonw/datasette-render-image-tags/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-render-image-tags/blob/main/LICENSE)
Turn any URLs ending in .jpg/.png/.gif into img tags with width 200
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-render-image-tags
## Usage
Once installed, any cells contaning a URL that ends with `.png` or `.jpg` or `.jpeg` or `.gif` will be rendered using an image tag, with a width of 200px.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-render-image-tags
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-render-image-tags,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-render-image-tags/,,https://pypi.org/project/datasette-render-image-tags/,"{""CI"": ""https://github.com/simonw/datasette-render-image-tags/actions"", ""Changelog"": ""https://github.com/simonw/datasette-render-image-tags/releases"", ""Homepage"": ""https://github.com/simonw/datasette-render-image-tags"", ""Issues"": ""https://github.com/simonw/datasette-render-image-tags/issues""}",https://pypi.org/project/datasette-render-image-tags/0.1/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.1,0,
datasette-sandstorm-support,Authentication and permissions for Datasette on Sandstorm,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-sandstorm-support
[](https://pypi.org/project/datasette-sandstorm-support/)
[](https://github.com/simonw/datasette-sandstorm-support/releases)
[](https://github.com/simonw/datasette-sandstorm-support/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-sandstorm-support/blob/main/LICENSE)
Authentication and permissions for Datasette on Sandstorm
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-sandstorm-support
## Usage
This plugin is part of [datasette-sandstorm](https://github.com/ocdtrekkie/datasette-sandstorm).
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-sandstorm-support
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-sandstorm-support,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-sandstorm-support/,,https://pypi.org/project/datasette-sandstorm-support/,"{""CI"": ""https://github.com/simonw/datasette-sandstorm-support/actions"", ""Changelog"": ""https://github.com/simonw/datasette-sandstorm-support/releases"", ""Homepage"": ""https://github.com/simonw/datasette-sandstorm-support"", ""Issues"": ""https://github.com/simonw/datasette-sandstorm-support/issues""}",https://pypi.org/project/datasette-sandstorm-support/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.2,0,
datasette-scale-to-zero,Quit Datasette if it has not received traffic for a specified time period,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-scale-to-zero
[](https://pypi.org/project/datasette-scale-to-zero/)
[](https://github.com/simonw/datasette-scale-to-zero/releases)
[](https://github.com/simonw/datasette-scale-to-zero/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-scale-to-zero/blob/main/LICENSE)
Quit Datasette if it has not received traffic for a specified time period
Some hosting providers such as [Fly](https://fly.io/) offer a scale to zero mechanism, where servers can shut down and will be automatically started when new traffic arrives.
This plugin can be used to configure Datasette to quit X minutes (or seconds, or hours) after the last request it received. It can also cause the Datasette server to exit after a configured maximum time whether or not it is receiving traffic.
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-scale-to-zero
## Configuration
This plugin will only take effect if it has been configured.
Add the following to your ``metadata.json`` or ``metadata.yml`` configuration file:
```json
{
""plugins"": {
""datasette-scale-to-zero"": {
""duration"": ""10m""
}
}
}
```
This will cause Datasette to quit if it has not received any HTTP traffic for 10 minutes.
You can set this value using a suffix of `m` for minutes, `h` for hours or `s` for seconds.
To cause Datasette to exit if the server has been running for longer than a specific time, use `""max-age""`:
```json
{
""plugins"": {
""datasette-scale-to-zero"": {
""max-age"": ""10h""
}
}
}
```
This example will exit the Datasette server if it has been running for more than ten hours.
You can use `""duration""` and `""max-age""` together in the same configuration file:
```json
{
""plugins"": {
""datasette-scale-to-zero"": {
""max-age"": ""10h"",
""duration"": ""5m""
}
}
}
```
This example will quit if no traffic has been received in five minutes, or if the server has been running for ten hours.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-scale-to-zero
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-scale-to-zero,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-scale-to-zero/,,https://pypi.org/project/datasette-scale-to-zero/,"{""CI"": ""https://github.com/simonw/datasette-scale-to-zero/actions"", ""Changelog"": ""https://github.com/simonw/datasette-scale-to-zero/releases"", ""Homepage"": ""https://github.com/simonw/datasette-scale-to-zero"", ""Issues"": ""https://github.com/simonw/datasette-scale-to-zero/issues""}",https://pypi.org/project/datasette-scale-to-zero/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.2,0,
datasette-sitemap,Generate sitemap.xml for Datasette sites,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-sitemap
[](https://pypi.org/project/datasette-sitemap/)
[](https://github.com/simonw/datasette-sitemap/releases)
[](https://github.com/simonw/datasette-sitemap/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-sitemap/blob/main/LICENSE)
Generate sitemap.xml for Datasette sites
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-sitemap
## Demo
This plugin is used for the sitemap on [til.simonwillison.net](https://til.simonwillison.net/):
- https://til.simonwillison.net/sitemap.xml
Here's [the configuration](https://github.com/simonw/til/blob/d4f67743a90a67100b46145986b2dec6f8d96583/metadata.yaml#L14-L16) used for that sitemap.
## Usage
Once configured, this plugin adds a sitemap at `/sitemap.xml` with a list of URLs.
This list is defined using a SQL query in `metadata.json` (or `.yml`) that looks like this:
```json
{
""plugins"": {
""datasette-sitemap"": {
""query"": ""select '/' || id as path from my_table""
}
}
}
```
Using `metadata.yml` allows for multi-line SQL queries which can be easier to maintain:
```yaml
plugins:
datasette-sitemap:
query: |
select
'/' || id as path
from
my_table
```
The SQL query must return a column called `path`. The values in this column must begin with a `/`. They will be used to generate a sitemap that looks like this:
```xml
https://example.com/1
https://example.com/2
```
You can use ``UNION`` in your SQL query to combine results from multiple tables, or include literal paths that you want to include in the index:
```sql
select
'/data/table1/' || id as path
from table1
union
select
'/data/table2/' || id as path
from table2
union
select
'/about' as path
```
If your Datasette instance has multiple databases you can configure the database to query using the `database` configuration property.
By default the domain name for the genearted URLs in the sitemap will be detected from the incoming request.
You can set `base_url` instead to override this. This should not include a trailing slash.
This example shows both of those settings, running the query against the `content` database and setting a custom base URL:
```yaml
plugins:
datasette-sitemap:
query: |
select '/plugins/' || name as path from plugins
union
select '/tools/' || name as path from tools
union
select '/news' as path
database: content
base_url: https://datasette.io
```
[Try that query](https://datasette.io/content?sql=select+%27%2Fplugins%2F%27+||+name+as+path+from+plugins%0D%0Aunion%0D%0Aselect+%27%2Ftools%2F%27+||+name+as+path+from+tools%0D%0Aunion%0D%0Aselect+%27%2Fnews%27+as+path%0D%0A).
## robots.txt
This plugin adds a `robots.txt` file pointing to the sitemap:
```
Sitemap: http://example.com/sitemap.xml
```
You can take full control of the sitemap by installing and configuring the [datasette-block-robots](https://datasette.io/plugins/datasette-block-robots) plugin.
This plugin will add the `Sitemap:` line even if you are using `datasette-block-robots` for the rest of your `robots.txt` file.
## Adding paths to the sitemap from other plugins
This plugin adds a new [plugin hook](https://docs.datasette.io/en/stable/plugin_hooks.html) to Datasete called `sitemap_extra_paths()` which can be used by other plugins to add their own additional lines to the `sitemap.xml` file.
The hook accepts these optional parameters:
- `datasette`: The current [Datasette instance](https://docs.datasette.io/en/stable/internals.html#datasette-class). You can use this to execute SQL queries or read plugin configuration settings.
- `request`: The [Request object](https://docs.datasette.io/en/stable/internals.html#request-object) representing the incoming request to `/sitemap.xml`.
The hook should return a list of strings, each representing a path to be added to the sitemap. Each path must begin with a `/`.
It can also return an `async def` function, which will be awaited and used to generate a list of lines. Use this option if you need to make `await` calls inside you hook implementation.
This example uses the hook to add two extra paths, one of which came from a SQL query:
```python
from datasette import hookimpl
@hookimpl
def sitemap_extra_paths(datasette):
async def inner():
db = datasette.get_database()
path_from_db = (await db.execute(""select '/example'"")).single_value()
return [""/about"", path_from_db]
return inner
```
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-sitemap
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-sitemap,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-sitemap/,,https://pypi.org/project/datasette-sitemap/,"{""CI"": ""https://github.com/simonw/datasette-sitemap/actions"", ""Changelog"": ""https://github.com/simonw/datasette-sitemap/releases"", ""Homepage"": ""https://github.com/simonw/datasette-sitemap"", ""Issues"": ""https://github.com/simonw/datasette-sitemap/issues""}",https://pypi.org/project/datasette-sitemap/1.0/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""datasette-block-robots ; extra == 'test'""]",>=3.7,1.0,0,
datasette-socrata,Import data from Socrata into Datasette,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-socrata
[](https://pypi.org/project/datasette-socrata/)
[](https://github.com/simonw/datasette-socrata/releases)
[](https://github.com/simonw/datasette-socrata/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-socrata/blob/main/LICENSE)
Import data from Socrata into Datasette
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-socrata
## Usage
Make sure you have [enabled WAL mode](https://til.simonwillison.net/sqlite/enabling-wal-mode) on your database files before using this plugin.
Once installed, an interface for importing data from Socrata will become available at this URL:
/-/import-socrata
Users will be able to paste in a URL to a dataset on Socrata in order to initialize an import.
You can also pre-fill the form by passing a `?url=` parameter, for example:
/-/import-socrata?url=https://data.sfgov.org/City-Infrastructure/Street-Tree-List/tkzw-k3nq
Any database that is attached to Datasette, is NOT loaded as immutable (with the `-i` option) and that has WAL mode enabled will be available for users to import data into.
The `import-socrata` permission governs access. By default the `root` actor (accessible using `datasette --root` to start Datasette) is granted that permission.
You can use permission plugins such as [datasette-permissions-sql](https://github.com/simonw/datasette-permissions-sql) to grant additional access to other users.
## Configuration
If you only want Socrata imports to be allowed to a specific database, you can configure that using plugin configration in `metadata.yml`:
```yaml
plugins:
datasette-socrata:
database: socrata
```
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-socrata
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-socrata,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-socrata/,,https://pypi.org/project/datasette-socrata/,"{""CI"": ""https://github.com/simonw/datasette-socrata/actions"", ""Changelog"": ""https://github.com/simonw/datasette-socrata/releases"", ""Homepage"": ""https://github.com/simonw/datasette-socrata"", ""Issues"": ""https://github.com/simonw/datasette-socrata/issues""}",https://pypi.org/project/datasette-socrata/0.3/,"[""datasette"", ""sqlite-utils (>=3.27)"", ""datasette-low-disk-space-hook"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'"", ""pytest-httpx ; extra == 'test'""]",>=3.7,0.3,0,
datasette-sqlite-fts4,Datasette plugin exposing SQL functions from sqlite-fts4,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-sqlite-fts4
[](https://pypi.org/project/datasette-sqlite-fts4/)
[](https://github.com/simonw/datasette-sqlite-fts4/releases)
[](https://github.com/simonw/datasette-sqlite-fts4/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-sqlite-fts4/blob/main/LICENSE)
Datasette plugin that exposes the custom SQL functions from [sqlite-fts4](https://github.com/simonw/sqlite-fts4).
[Interactive demo](https://datasette-sqlite-fts4.datasette.io/24ways-fts4?sql=select%0D%0A++++json_object%28%0D%0A++++++++""label""%2C+articles.title%2C+""href""%2C+articles.url%0D%0A++++%29+as+article%2C%0D%0A++++articles.author%2C%0D%0A++++rank_score%28matchinfo%28articles_fts%2C+""pcx""%29%29+as+score%2C%0D%0A++++rank_bm25%28matchinfo%28articles_fts%2C+""pcnalx""%29%29+as+bm25%2C%0D%0A++++json_object%28%0D%0A++++++++""pre""%2C+annotate_matchinfo%28matchinfo%28articles_fts%2C+""pcxnalyb""%29%2C+""pcxnalyb""%29%0D%0A++++%29+as+annotated_matchinfo%2C%0D%0A++++matchinfo%28articles_fts%2C+""pcxnalyb""%29+as+matchinfo%2C%0D%0A++++decode_matchinfo%28matchinfo%28articles_fts%2C+""pcxnalyb""%29%29+as+decoded_matchinfo%0D%0Afrom%0D%0A++++articles_fts+join+articles+on+articles.rowid+%3D+articles_fts.rowid%0D%0Awhere%0D%0A++++articles_fts+match+%3Asearch%0D%0Aorder+by+bm25&search=jquery+maps). Read [Exploring search relevance algorithms with SQLite](https://simonwillison.net/2019/Jan/7/exploring-search-relevance-algorithms-sqlite/) for further details on this project.
## Installation
pip install datasette-sqlite-fts4
If you are deploying a database using `datasette publish` you can include this plugin using the `--install` option:
datasette publish now mydb.db --install=datasette-sqlite-fts4
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-sqlite-fts4,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-sqlite-fts4/,,https://pypi.org/project/datasette-sqlite-fts4/,"{""CI"": ""https://github.com/simonw/datasette-sqlite-fts4/actions"", ""Changelog"": ""https://github.com/simonw/datasette-sqlite-fts4/releases"", ""Homepage"": ""https://github.com/simonw/datasette-sqlite-fts4"", ""Issues"": ""https://github.com/simonw/datasette-sqlite-fts4/issues""}",https://pypi.org/project/datasette-sqlite-fts4/0.3.2/,"[""datasette"", ""sqlite-fts4 (>=1.0.3)"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.7,0.3.2,0,
datasette-tiddlywiki,Run TiddlyWiki in Datasette and save Tiddlers to a SQLite database,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-tiddlywiki
[](https://pypi.org/project/datasette-tiddlywiki/)
[](https://github.com/simonw/datasette-tiddlywiki/releases)
[](https://github.com/simonw/datasette-tiddlywiki/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-tiddlywiki/blob/main/LICENSE)
Run [TiddlyWiki](https://tiddlywiki.com/) in Datasette and save Tiddlers to a SQLite database
## Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-tiddlywiki
## Usage
Start Datasette with a `tiddlywiki.db` database. You can create it if it does not yet exist using `--create`.
You need to be signed in as the `root` user to write to the wiki, so use the `--root` option and click on the link it provides:
% datasette tiddlywiki.db --create --root
http://127.0.0.1:8001/-/auth-token?token=456670f1e8d01a8a33b71e17653130de17387336e29afcdfb4ab3d18261e6630
# ...
Navigate to `/-/tiddlywiki` on your instance to interact with TiddlyWiki.
## Authentication and permissions
By default, the wiki can be read by anyone who has permission to read the `tiddlywiki.db` database. Only the signed in `root` user can write to it.
You can sign in using the `--root` option described above, or you can set a password for that user using the [datasette-auth-passwords](https://datasette.io/plugins/datasette-auth-passwords) plugin and sign in using the `/-/login` page.
You can use the `edit-tiddlywiki` permission to grant edit permisions to other users, using another plugin such as [datasette-permissions-sql](https://datasette.io/plugins/datasette-permissions-sql).
You can use the `view-database` permission against the `tiddlywiki` database to control who can view the wiki.
Datasette's permissions mechanism is described in full in [the Datasette documentation](https://docs.datasette.io/en/stable/authentication.html).
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-tiddlywiki
python3 -mvenv venv
source venv/bin/activate
Or if you are using `pipenv`:
pipenv shell
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
",Simon Willison,,text/markdown,https://github.com/simonw/datasette-tiddlywiki,,"Apache License, Version 2.0",,,https://pypi.org/project/datasette-tiddlywiki/,,https://pypi.org/project/datasette-tiddlywiki/,"{""CI"": ""https://github.com/simonw/datasette-tiddlywiki/actions"", ""Changelog"": ""https://github.com/simonw/datasette-tiddlywiki/releases"", ""Homepage"": ""https://github.com/simonw/datasette-tiddlywiki"", ""Issues"": ""https://github.com/simonw/datasette-tiddlywiki/issues""}",https://pypi.org/project/datasette-tiddlywiki/0.2/,"[""datasette"", ""pytest ; extra == 'test'"", ""pytest-asyncio ; extra == 'test'""]",>=3.6,0.2,0,
datasette-total-page-time,Add a note to the Datasette footer measuring the total page load time,"[""Framework :: Datasette"", ""License :: OSI Approved :: Apache Software License""]","# datasette-total-page-time
[](https://pypi.org/project/datasette-total-page-time/)
[](https://github.com/simonw/datasette-total-page-time/releases)
[](https://github.com/simonw/datasette-total-page-time/actions?query=workflow%3ATest)
[](https://github.com/simonw/datasette-total-page-time/blob/main/LICENSE)
Add a note to the Datasette footer measuring the total page load time
## Installation
Install this plugin in the same environment as Datasette.
datasette install datasette-total-page-time
## Usage
Once this plugin is installed, a note will appear in the footer of every page showing how long the page took to generate.
> Queries took 326.74ms · Page took 386.310ms
## How it works
Measuring how long a page takes to load and then injecting that note into the page is tricky, because you need to finish generating the page before you know how long it took to load it!
This plugin uses the [asgi_wrapper](https://docs.datasette.io/en/stable/plugin_hooks.html#asgi-wrapper-datasette) plugin hook to measure the time taken by Datasette and then inject the following JavaScript at the bottom of the response, after the closing `