pypi_packages
39 rows where classifiers contains "License :: OSI Approved :: Apache Software License"
This data as json, CSV (advanced)
Suggested facets: classifiers, author, requires_dist, requires_python, version, classifiers (array), requires_dist (array)
| name ▼ | summary | classifiers | description | author | author_email | description_content_type | home_page | keywords | license | maintainer | maintainer_email | package_url | platform | project_url | project_urls | release_url | requires_dist | requires_python | version | yanked | yanked_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| csv-diff | Python CLI tool and library for diffing CSV and JSON files | ["Development Status :: 4 - Beta", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7"] | # csv-diff [](https://pypi.org/project/csv-diff/) [](https://github.com/simonw/csv-diff/releases) [](https://github.com/simonw/csv-diff/actions?query=workflow%3ATest) [](https://github.com/simonw/csv-diff/blob/main/LICENSE) Tool for viewing the difference between two CSV, TSV or JSON files. See [Generating a commit log for San Francisco’s official list of trees](https://simonwillison.net/2019/Mar/13/tree-history/) (and the [sf-tree-history repo commit log](https://github.com/simonw/sf-tree-history/commits)) for background information on this project. ## Installation pip install csv-diff ## Usage Consider two CSV files: `one.csv` id,name,age 1,Cleo,4 2,Pancakes,2 `two.csv` id,name,age 1,Cleo,5 3,Bailey,1 `csv-diff` can show a human-readable summary of differences between the files: $ csv-diff one.csv two.csv --key=id 1 row changed, 1 row added, 1 row removed 1 row changed Row 1 age: "4" => "5" 1 row added id: 3 name: Bailey age: 1 1 row removed id: 2 name: Pancakes age: 2 The `--key=id` option means that the `id` column should be treated as the unique key, to identify which records have changed. The tool will automatically detect if your files are comma- or tab-separated. You can over-ride this automatic detection and force the tool to use a specific format using `--format=tsv` or `--format=csv`. You can also feed it JSON files, provided they are a JSON array of objects where each object has the same keys. Use `--format=json` if your input files are JSON. Use `--show-unchanged` to include full details of the unchanged values for rows with at least one change in the diff output: % csv-diff one.csv two.c… | Simon Willison | text/markdown | https://github.com/simonw/csv-diff | Apache License, Version 2.0 | https://pypi.org/project/csv-diff/ | https://pypi.org/project/csv-diff/ | {"Homepage": "https://github.com/simonw/csv-diff"} | https://pypi.org/project/csv-diff/1.1/ | ["click", "dictdiffer", "pytest ; extra == 'test'"] | 1.1 | 0 | |||||||
| csvs-to-sqlite | Convert CSV files into a SQLite database | ["Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7", "Programming Language :: Python :: 3.8", "Programming Language :: Python :: 3.9", "Topic :: Database"] | # csvs-to-sqlite [](https://pypi.org/project/csvs-to-sqlite/) [](https://github.com/simonw/csvs-to-sqlite/releases) [](https://github.com/simonw/csvs-to-sqlite/actions?query=workflow%3ATest) [](https://github.com/simonw/csvs-to-sqlite/blob/main/LICENSE) Convert CSV files into a SQLite database. Browse and publish that SQLite database with [Datasette](https://github.com/simonw/datasette). Basic usage: csvs-to-sqlite myfile.csv mydatabase.db This will create a new SQLite database called `mydatabase.db` containing a single table, `myfile`, containing the CSV content. You can provide multiple CSV files: csvs-to-sqlite one.csv two.csv bundle.db The `bundle.db` database will contain two tables, `one` and `two`. This means you can use wildcards: csvs-to-sqlite ~/Downloads/*.csv my-downloads.db If you pass a path to one or more directories, the script will recursively search those directories for CSV files and create tables for each one. csvs-to-sqlite ~/path/to/directory all-my-csvs.db ## Handling TSV (tab-separated values) You can use the `-s` option to specify a different delimiter. If you want to use a tab character you'll need to apply shell escaping like so: csvs-to-sqlite my-file.tsv my-file.db -s $'\t' ## Refactoring columns into separate lookup tables Let's say you have a CSV file that looks like this: county,precinct,office,district,party,candidate,votes Clark,1,President,,REP,John R. Kasich,5 Clark,2,President,,REP,John R. Kasich,0 Clark,3,President,,REP,John R. Kasich,7 ([Real example taken from the Open Elections project](https://github.com/openelections/openelections-data-sd/blob/master/2016/20160607__sd__primary__clark__precinct.csv)) You can n… | Simon Willison | text/markdown | https://github.com/simonw/csvs-to-sqlite | Apache License, Version 2.0 | https://pypi.org/project/csvs-to-sqlite/ | https://pypi.org/project/csvs-to-sqlite/ | {"Homepage": "https://github.com/simonw/csvs-to-sqlite"} | https://pypi.org/project/csvs-to-sqlite/1.3/ | ["click (~=7.0)", "dateparser (>=1.0)", "pandas (>=1.0)", "py-lru-cache (~=0.1.4)", "six", "pytest ; extra == 'test'", "cogapp ; extra == 'test'"] | 1.3 | 0 | |||||||
| datasette | An open source multi-tool for exploring and publishing data | ["Development Status :: 4 - Beta", "Framework :: Datasette", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.10", "Programming Language :: Python :: 3.7", "Programming Language :: Python :: 3.8", "Programming Language :: Python :: 3.9", "Topic :: Database"] | <img src="https://datasette.io/static/datasette-logo.svg" alt="Datasette"> [](https://pypi.org/project/datasette/) [](https://docs.datasette.io/en/stable/changelog.html) [](https://pypi.org/project/datasette/) [](https://github.com/simonw/datasette/actions?query=workflow%3ATest) [](https://docs.datasette.io/en/latest/?badge=latest) [](https://github.com/simonw/datasette/blob/main/LICENSE) [](https://hub.docker.com/r/datasetteproject/datasette) [](https://discord.gg/ktd74dm5mw) *An open source multi-tool for exploring and publishing data* Datasette is a tool for exploring and publishing data. It helps people take data of any shape or size and publish that as an interactive, explorable website and accompanying API. Datasette is aimed at data journalists, museum curators, archivists, local governments, scientists, researchers and anyone else who has data that they wish to share with the world. [Explore a demo](https://global-power-plants.datasettes.com/global-power-plants/global-power-plants), watch [a video about the project](https://simonwillison.net/2021/Feb/7/video/) or try it out by [uploading and publishing your own CSV data](https://docs.datasette.io/en/stable/getting_started.html#try-datasette-without-installing-anything-using-glitch). * [datasette.io](https://datasette.io/) is the official project website * Latest [Datasette News](https://datasette.io/news) * Comprehensive documentation: https://docs.dat… | Simon Willison | text/markdown | https://datasette.io/ | Apache License, Version 2.0 | https://pypi.org/project/datasette/ | https://pypi.org/project/datasette/ | {"CI": "https://github.com/simonw/datasette/actions?query=workflow%3ATest", "Changelog": "https://docs.datasette.io/en/stable/changelog.html", "Documentation": "https://docs.datasette.io/en/stable/", "Homepage": "https://datasette.io/", "Issues": "https://github.com/simonw/datasette/issues", "Live demo": "https://latest.datasette.io/", "Source code": "https://github.com/simonw/datasette"} | https://pypi.org/project/datasette/0.63.1/ | ["asgiref (>=3.2.10)", "click (>=7.1.1)", "click-default-group-wheel (>=1.2.2)", "Jinja2 (>=2.10.3)", "hupper (>=1.9)", "httpx (>=0.20)", "pint (>=0.9)", "pluggy (>=1.0)", "uvicorn (>=0.11)", "aiofiles (>=0.4)", "janus (>=0.6.2)", "asgi-csrf (>=0.9)", "PyYAML (>=5.3)", "mergedeep (>=1.1.1)", "itsdangerous (>=1.1)", "furo (==2022.9.29) ; extra == 'docs'", "sphinx-autobuild ; extra == 'docs'", "codespell ; extra == 'docs'", "blacken-docs ; extra == 'docs'", "sphinx-copybutton ; extra == 'docs'", "rich ; extra == 'rich'", "pytest (>=5.2.2) ; extra == 'test'", "pytest-xdist (>=2.2.1) ; extra == 'test'", "pytest-asyncio (>=0.17) ; extra == 'test'", "beautifulsoup4 (>=4.8.1) ; extra == 'test'", "black (==22.10.0) ; extra == 'test'", "blacken-docs (==1.12.1) ; extra == 'test'", "pytest-timeout (>=1.4.2) ; extra == 'test'", "trustme (>=0.7) ; extra == 'test'", "cogapp (>=3.3.0) ; extra == 'test'"] | >=3.7 | 0.63.1 | 0 | ||||||
| datasette-auth0 | Datasette plugin that authenticates users using Auth0 | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-auth0 [](https://pypi.org/project/datasette-auth0/) [](https://github.com/simonw/datasette-auth0/releases) [](https://github.com/simonw/datasette-auth0/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-auth0/blob/main/LICENSE) Datasette plugin that authenticates users using [Auth0](https://auth0.com/) See [Simplest possible OAuth authentication with Auth0](https://til.simonwillison.net/auth0/oauth-with-auth0) for more about how this plugin works. ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-auth0 ## Demo You can try this out at [datasette-auth0-demo.datasette.io](https://datasette-auth0-demo.datasette.io/) - click on the top right menu icon and select "Sign in with Auth0". ## Initial configuration First, create a new application in Auth0. You will need the domain, client ID and client secret for that application. The domain should be something like `mysite.us.auth0.com`. Add `http://127.0.0.1:8001/-/auth0-callback` to the list of Allowed Callback URLs. Then configure these plugin secrets using `metadata.yml`: ```yaml plugins: datasette-auth0: domain: "$env": AUTH0_DOMAIN client_id: "$env": AUTH0_CLIENT_ID client_secret: "$env": AUTH0_CLIENT_SECRET ``` Only the `client_secret` needs to be kept secret, but for consistency I recommend using the `$env` mechanism for all three. In development, you can run Datasette and pass in environment variables like this: ``` AUTH0_DOMAIN="your-domain.us.auth0.com" \ AUTH0_CLIENT_ID="...client-id-goes-here..." \ AUTH0_CLIENT_SECRET="...secret-goes-here..." \ datasette -m metadata.yml ``` If you are deploying using `datasette publi… | Simon Willison | text/markdown | https://github.com/simonw/datasette-auth0 | Apache License, Version 2.0 | https://pypi.org/project/datasette-auth0/ | https://pypi.org/project/datasette-auth0/ | {"CI": "https://github.com/simonw/datasette-auth0/actions", "Changelog": "https://github.com/simonw/datasette-auth0/releases", "Homepage": "https://github.com/simonw/datasette-auth0", "Issues": "https://github.com/simonw/datasette-auth0/issues"} | https://pypi.org/project/datasette-auth0/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "pytest-httpx ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-cluster-map | Datasette plugin that shows a map for any data with latitude/longitude columns | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-cluster-map [](https://pypi.org/project/datasette-cluster-map/) [](https://github.com/simonw/datasette-cluster-map/releases) [](https://github.com/simonw/datasette-cluster-map/blob/main/LICENSE) A [Datasette plugin](https://docs.datasette.io/en/stable/plugins.html) that detects tables with `latitude` and `longitude` columns and then plots them on a map using [Leaflet.markercluster](https://github.com/Leaflet/Leaflet.markercluster). More about this project: [Datasette plugins, and building a clustered map visualization](https://simonwillison.net/2018/Apr/20/datasette-plugins/). ## Demo [global-power-plants.datasettes.com](https://global-power-plants.datasettes.com/global-power-plants/global-power-plants) hosts a demo of this plugin running against a database of 33,000 power plants around the world. 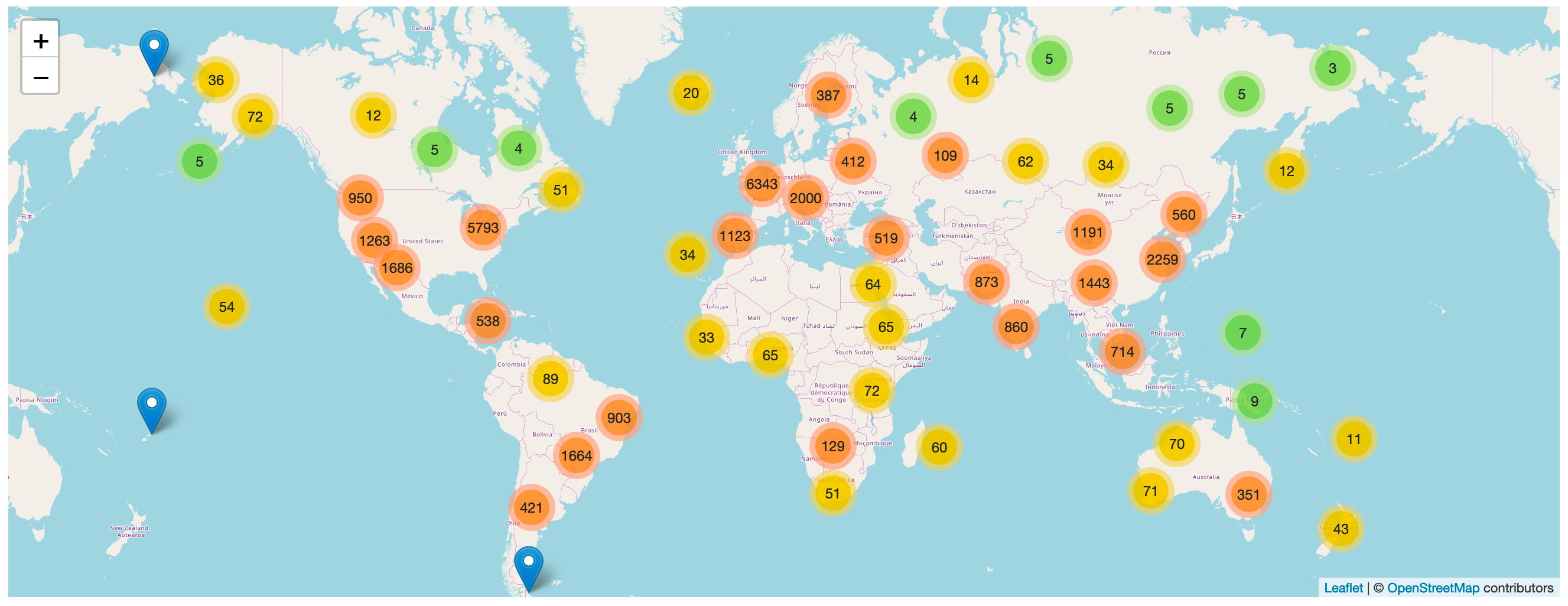 ## Installation Run `datasette install datasette-cluster-map` to add this plugin to your Datasette virtual environment. Datasette will automatically load the plugin if it is installed in this way. If you are deploying using the `datasette publish` command you can use the `--install` option: datasette publish cloudrun mydb.db --install=datasette-cluster-map If any of your tables have a `latitude` and `longitude` column, a map will be automatically displayed. ## Configuration If your columns are called something else you can configure the column names using [plugin configuration](https://docs.datasette.io/en/stable/plugins.html#plugin-configuration) in a `metadata.json` file. For example, if all of your columns are called `xlat` and `xlng` you can create a `metadata.json` file like this: ```json { "title": "Regular metadata keys can go here too", "p… | Simon Willison | text/markdown | https://github.com/simonw/datasette-cluster-map | Apache License, Version 2.0 | https://pypi.org/project/datasette-cluster-map/ | https://pypi.org/project/datasette-cluster-map/ | {"CI": "https://github.com/simonw/datasette-cluster-map/actions", "Changelog": "https://github.com/simonw/datasette-cluster-map/releases", "Homepage": "https://github.com/simonw/datasette-cluster-map", "Issues": "https://github.com/simonw/datasette-cluster-map/issues"} | https://pypi.org/project/datasette-cluster-map/0.17.2/ | ["datasette (>=0.54)", "datasette-leaflet (>=0.2.2)", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "httpx ; extra == 'test'", "sqlite-utils ; extra == 'test'"] | 0.17.2 | 0 | |||||||
| datasette-copy-to-memory | Copy database files into an in-memory database on startup | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-copy-to-memory [](https://pypi.org/project/datasette-copy-to-memory/) [](https://github.com/simonw/datasette-copy-to-memory/releases) [](https://github.com/simonw/datasette-copy-to-memory/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-copy-to-memory/blob/main/LICENSE) Copy database files into an in-memory database on startup This plugin is **highly experimental**. It currently exists to support Datasette performance research, and is not designed for actual production usage. ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-copy-to-memory ## Usage On startup, Datasette will create an in-memory named database for each attached database. This database will have the same name but with `_memory` at the end. So running this: datasette fixtures.db Will serve two databases: the original at `/fixtures` and the in-memory copy at `/fixtures_memory`. ## Demo A demo is running on [latest-with-plugins.datasette.io](https://latest-with-plugins.datasette.io/) - the [/fixtures_memory](https://latest-with-plugins.datasette.io/fixtures_memory) table there is provided by this plugin. ## Configuration By default every attached database file will be loaded into a `_memory` copy. You can use plugin configuration to specify just a subset of the database. For example, to create `github_memory` but not `fixtures_memory` you would use the following `metadata.yml` file: ```yaml plugins: datasette-copy-to-memory: databases: - github ``` Then start Datasette like this: datasette github.db fixtures.db -m metadata.yml If you don't want to have a `fixtures` and `fixtures_memory` data… | Simon Willison | text/markdown | https://github.com/simonw/datasette-copy-to-memory | Apache License, Version 2.0 | https://pypi.org/project/datasette-copy-to-memory/ | https://pypi.org/project/datasette-copy-to-memory/ | {"CI": "https://github.com/simonw/datasette-copy-to-memory/actions", "Changelog": "https://github.com/simonw/datasette-copy-to-memory/releases", "Homepage": "https://github.com/simonw/datasette-copy-to-memory", "Issues": "https://github.com/simonw/datasette-copy-to-memory/issues"} | https://pypi.org/project/datasette-copy-to-memory/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "sqlite-utils ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-expose-env | Datasette plugin to expose selected environment variables at /-/env for debugging | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-expose-env [](https://pypi.org/project/datasette-expose-env/) [](https://github.com/simonw/datasette-expose-env/releases) [](https://github.com/simonw/datasette-expose-env/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-expose-env/blob/main/LICENSE) Datasette plugin to expose selected environment variables at `/-/env` for debugging ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-expose-env ## Configuration Decide on a list of environment variables you would like to expose, then add the following to your `metadata.yml` configuration: ```yaml plugins: datasette-expose-env: - ENV_VAR_1 - ENV_VAR_2 - ENV_VAR_3 ``` If you are using JSON in a `metadata.json` file use the following: ```json { "plugins": { "datasette-expose-env": [ "ENV_VAR_1", "ENV_VAR_2", "ENV_VAR_3" ] } } ``` Visit `/-/env` on your Datasette instance to see the values of the environment variables. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-expose-env python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-expose-env | Apache License, Version 2.0 | https://pypi.org/project/datasette-expose-env/ | https://pypi.org/project/datasette-expose-env/ | {"CI": "https://github.com/simonw/datasette-expose-env/actions", "Changelog": "https://github.com/simonw/datasette-expose-env/releases", "Homepage": "https://github.com/simonw/datasette-expose-env", "Issues": "https://github.com/simonw/datasette-expose-env/issues"} | https://pypi.org/project/datasette-expose-env/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-external-links-new-tabs | Datasette plugin to open external links in new tabs | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-external-links-new-tabs [](https://pypi.org/project/datasette-external-links-new-tabs/) [](https://github.com/ocdtrekkie/datasette-external-links-new-tabs/releases) [](https://github.com/ocdtrekkie/datasette-external-links-new-tabs/actions?query=workflow%3ATest) [](https://github.com/ocdtrekkie/datasette-external-links-new-tabs/blob/main/LICENSE) Datasette plugin to open external links in new tabs ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-external-links-new-tabs ## Usage There are no usage instructions, it simply opens external links in a new tab. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-external-links-new-tabs python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Jacob Weisz | text/markdown | https://github.com/ocdtrekkie/datasette-external-links-new-tabs | Apache License, Version 2.0 | https://pypi.org/project/datasette-external-links-new-tabs/ | https://pypi.org/project/datasette-external-links-new-tabs/ | {"CI": "https://github.com/ocdtrekkie/datasette-external-links-new-tabs/actions", "Changelog": "https://github.com/ocdtrekkie/datasette-external-links-new-tabs/releases", "Homepage": "https://github.com/ocdtrekkie/datasette-external-links-new-tabs", "Issues": "https://github.com/ocdtrekkie/datasette-external-links-new-tabs/issues"} | https://pypi.org/project/datasette-external-links-new-tabs/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-gunicorn | Run a Datasette server using Gunicorn | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-gunicorn [](https://pypi.org/project/datasette-gunicorn/) [](https://github.com/simonw/datasette-gunicorn/releases) [](https://github.com/simonw/datasette-gunicorn/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-gunicorn/blob/main/LICENSE) Run a [Datasette](https://datasette.io/) server using [Gunicorn](https://gunicorn.org/) ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-gunicorn ## Usage The plugin adds a new `datasette gunicorn` command. This takes most of the same options as `datasette serve`, plus one more option for setting the number of Gunicorn workers to start: `-w/--workers X` - set the number of workers. Defaults to 1. To start serving a database using 4 workers, run the following: datasette gunicorn fixtures.db -w 4 It is advisable to switch your datasette [into WAL mode](https://til.simonwillison.net/sqlite/enabling-wal-mode) to get the best performance out of this configuration: sqlite3 fixtures.db 'PRAGMA journal_mode=WAL;' Run `datasette gunicorn --help` for a full list of options (which are the same as `datasette serve --help`, with the addition of the new `-w` option). ## datasette gunicorn --help Not all of the options to `datasette serve` are supported. Here's the full list of available options: <!-- [[[cog import cog from datasette import cli from click.testing import CliRunner runner = CliRunner() result = runner.invoke(cli.cli, ["gunicorn", "--help"]) help = result.output.replace("Usage: cli", "Usage: datasette") cog.out( "```\n{}\n```".format(help) ) ]]] --> ``` Usage: datasette gunicorn [OPTIONS] [FILES]... Start a Gunicorn server running to serve … | Simon Willison | text/markdown | https://github.com/simonw/datasette-gunicorn | Apache License, Version 2.0 | https://pypi.org/project/datasette-gunicorn/ | https://pypi.org/project/datasette-gunicorn/ | {"CI": "https://github.com/simonw/datasette-gunicorn/actions", "Changelog": "https://github.com/simonw/datasette-gunicorn/releases", "Homepage": "https://github.com/simonw/datasette-gunicorn", "Issues": "https://github.com/simonw/datasette-gunicorn/issues"} | https://pypi.org/project/datasette-gunicorn/0.1/ | ["datasette", "gunicorn", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "cogapp ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-gzip | Add gzip compression to Datasette | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-gzip [](https://pypi.org/project/datasette-gzip/) [](https://github.com/simonw/datasette-gzip/releases) [](https://github.com/simonw/datasette-gzip/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-gzip/blob/main/LICENSE) Add gzip compression to Datasette ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-gzip ## Usage Once installed, Datasette will obey the `Accept-Encoding:` header sent by browsers or other user agents and return content compressed in the most appropriate way. This plugin is a thin wrapper for the [asgi-gzip library](https://github.com/simonw/asgi-gzip), which extracts the [GzipMiddleware](https://www.starlette.io/middleware/#gzipmiddleware) from Starlette. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-gzip python3 -mvenv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-gzip | Apache License, Version 2.0 | https://pypi.org/project/datasette-gzip/ | https://pypi.org/project/datasette-gzip/ | {"CI": "https://github.com/simonw/datasette-gzip/actions", "Changelog": "https://github.com/simonw/datasette-gzip/releases", "Homepage": "https://github.com/simonw/datasette-gzip", "Issues": "https://github.com/simonw/datasette-gzip/issues"} | https://pypi.org/project/datasette-gzip/0.2/ | ["datasette", "asgi-gzip", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-hashed-urls | Optimize Datasette performance behind a caching proxy | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-hashed-urls [](https://pypi.org/project/datasette-hashed-urls/) [](https://github.com/simonw/datasette-hashed-urls/releases) [](https://github.com/simonw/datasette-hashed-urls/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-hashed-urls/blob/main/LICENSE) Optimize Datasette performance behind a caching proxy When you open a database file in immutable mode using the `-i` option, Datasette calculates a SHA-256 hash of the contents of that file on startup. This content hash can then optionally be used to create URLs that are guaranteed to change if the contents of the file changes in the future. The result is pages that can be cached indefinitely by both browsers and caching proxies - providing a significant performance boost. ## Demo A demo of this plugin is running at https://datasette-hashed-urls.vercel.app/ ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-hashed-urls ## Usage Once installed, this plugin will act on any immutable database files that are loaded into Datasette: datasette -i fixtures.db The database will automatically be renamed to incorporate a hash of the contents of the SQLite file - so the above database would be served as: http://127.0.0.1:8001/fixtures-aa7318b Every page that accesss that database, including JSON endpoints, will be served with the following far-future cache expiry header: cache-control: max-age=31536000, public Here `max-age=31536000` is the number of seconds in a year. A caching proxy such as Cloudflare can then be used to cache and accelerate content served by Datasette. When the database file is updated and the server is re… | Simon Willison | text/markdown | https://github.com/simonw/datasette-hashed-urls | Apache License, Version 2.0 | https://pypi.org/project/datasette-hashed-urls/ | https://pypi.org/project/datasette-hashed-urls/ | {"CI": "https://github.com/simonw/datasette-hashed-urls/actions", "Changelog": "https://github.com/simonw/datasette-hashed-urls/releases", "Homepage": "https://github.com/simonw/datasette-hashed-urls", "Issues": "https://github.com/simonw/datasette-hashed-urls/issues"} | https://pypi.org/project/datasette-hashed-urls/0.4/ | ["datasette (>=0.61.1)", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "sqlite-utils ; extra == 'test'"] | >=3.7 | 0.4 | 0 | ||||||
| datasette-hovercards | Add preview hovercards to links in Datasette | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-hovercards [](https://pypi.org/project/datasette-hovercards/) [](https://github.com/simonw/datasette-hovercards/releases) [](https://github.com/simonw/datasette-hovercards/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-hovercards/blob/main/LICENSE) Add preview hovercards to links in Datasette ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-hovercards ## Usage Once installed, hovering over a link to a row within the Datasette interface - for example a foreign key reference on the table page - should show a hovercard with a preview of that row. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-hovercards python3 -mvenv venv source venv/bin/activate Or if you are using `pipenv`: pipenv shell Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-hovercards | Apache License, Version 2.0 | https://pypi.org/project/datasette-hovercards/ | https://pypi.org/project/datasette-hovercards/ | {"CI": "https://github.com/simonw/datasette-hovercards/actions", "Changelog": "https://github.com/simonw/datasette-hovercards/releases", "Homepage": "https://github.com/simonw/datasette-hovercards", "Issues": "https://github.com/simonw/datasette-hovercards/issues"} | https://pypi.org/project/datasette-hovercards/0.1a0/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.6 | 0.1a0 | 0 | ||||||
| datasette-ics | Datasette plugin for outputting iCalendar files | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-ics [](https://pypi.org/project/datasette-ics/) [](https://github.com/simonw/datasette-ics/releases) [](https://github.com/simonw/datasette-ics/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-ics/blob/main/LICENSE) Datasette plugin that adds support for generating [iCalendar .ics files](https://tools.ietf.org/html/rfc5545) with the results of a SQL query. ## Installation Install this plugin in the same environment as Datasette to enable the `.ics` output extension. $ pip install datasette-ics ## Usage To create an iCalendar file you need to define a custom SQL query that returns a required set of columns: * `event_name` - the short name for the event * `event_dtstart` - when the event starts The following columns are optional: * `event_dtend` - when the event ends * `event_duration` - the duration of the event (use instead of `dtend`) * `event_description` - a longer description of the event * `event_uid` - a globally unique identifier for this event * `event_tzid` - the timezone for the event, e.g. `America/Chicago` A query that returns these columns can then be returned as an ics feed by adding the `.ics` extension. ## Demo [This SQL query]([https://www.rockybeaches.com/data?sql=with+inner+as+(%0D%0A++select%0D%0A++++datetime%2C%0D%0A++++substr(datetime%2C+0%2C+11)+as+date%2C%0D%0A++++mllw_feet%2C%0D%0A++++lag(mllw_feet)+over+win+as+previous_mllw_feet%2C%0D%0A++++lead(mllw_feet)+over+win+as+next_mllw_feet%0D%0A++from%0D%0A++++tide_predictions%0D%0A++where%0D%0A++++station_id+%3D+%3Astation_id%0D%0A++++and+datetime+%3E%3D+date()%0D%0A++++window+win+as+(%0D%0A++++++order+by%0D%0A++++++++datetime%0D%0A++++)%0D%0A++order+by%0D%0A++++datetime%0D%0A)%2C%0D%0Alowe… | Simon Willison | text/markdown | https://github.com/simonw/datasette-ics | Apache License, Version 2.0 | https://pypi.org/project/datasette-ics/ | https://pypi.org/project/datasette-ics/ | {"CI": "https://github.com/simonw/datasette-ics/actions", "Changelog": "https://github.com/simonw/datasette-ics/releases", "Homepage": "https://github.com/simonw/datasette-ics", "Issues": "https://github.com/simonw/datasette-ics/issues"} | https://pypi.org/project/datasette-ics/0.5.2/ | ["datasette (>=0.49)", "ics (==0.7.2)", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | 0.5.2 | 0 | |||||||
| datasette-mp3-audio | Turn .mp3 URLs into an audio player in the Datasette interface | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-mp3-audio [](https://pypi.org/project/datasette-mp3-audio/) [](https://github.com/simonw/datasette-mp3-audio/releases) [](https://github.com/simonw/datasette-mp3-audio/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-mp3-audio/blob/main/LICENSE) Turn .mp3 URLs into an audio player in the Datasette interface ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-mp3-audio ## Demo Try this plugin at [https://scotrail.datasette.io/scotrail/announcements](https://scotrail.datasette.io/scotrail/announcements) The demo uses ScotRail train announcements from [matteason/scotrail-announcements-june-2022](https://github.com/matteason/scotrail-announcements-june-2022). ## Usage Once installed, any cells with a value that ends in `.mp3` and starts with either `http://` or `/` or `https://` will be turned into an embedded HTML audio element like this: ```html <audio controls src="... value ...">Audio not supported</audio> ``` A "Play X MP3s on this page" button will be added to athe top of any table page listing more than one MP3. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-mp3-audio python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-mp3-audio | Apache License, Version 2.0 | https://pypi.org/project/datasette-mp3-audio/ | https://pypi.org/project/datasette-mp3-audio/ | {"CI": "https://github.com/simonw/datasette-mp3-audio/actions", "Changelog": "https://github.com/simonw/datasette-mp3-audio/releases", "Homepage": "https://github.com/simonw/datasette-mp3-audio", "Issues": "https://github.com/simonw/datasette-mp3-audio/issues"} | https://pypi.org/project/datasette-mp3-audio/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "sqlite-utils ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-multiline-links | Make multiple newline separated URLs clickable in Datasette | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-multiline-links [](https://pypi.org/project/datasette-multiline-links/) [](https://github.com/simonw/datasette-multiline-links/releases) [](https://github.com/simonw/datasette-multiline-links/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-multiline-links/blob/main/LICENSE) Make multiple newline separated URLs clickable in Datasette ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-multiline-links ## Usage Once installed, if a cell has contents like this: ``` https://example.com Not a link https://google.com ``` It will be rendered as: ```html <a href="https://example.com">https://example.com</a> Not a link <a href="https://google.com">https://google.com</a> ``` ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-multiline-links python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-multiline-links | Apache License, Version 2.0 | https://pypi.org/project/datasette-multiline-links/ | https://pypi.org/project/datasette-multiline-links/ | {"CI": "https://github.com/simonw/datasette-multiline-links/actions", "Changelog": "https://github.com/simonw/datasette-multiline-links/releases", "Homepage": "https://github.com/simonw/datasette-multiline-links", "Issues": "https://github.com/simonw/datasette-multiline-links/issues"} | https://pypi.org/project/datasette-multiline-links/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-nteract-data-explorer | automatic visual data explorer for datasette | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-nteract-data-explorer [](https://pypi.org/project/datasette-nteract-data-explorer/) [](https://github.com/hydrosquall/datasette-nteract-data-explorer/releases) [](https://github.com/hydrosquall/datasette-nteract-data-explorer/actions?query=workflow%3ATest) [](https://github.com/hydrosquall/datasette-nteract-data-explorer/blob/main/LICENSE) An automatic data visualization plugin for the [Datasette](https://datasette.io/) ecosystem. See your dataset from multiple views with an easy-to-use, customizable menu-based interface. ## Demo Try the [live demo](https://datasette-nteract-data-explorer.vercel.app/happy_planet_index/hpi_cleaned?_size=137)  _Running Datasette with the Happy Planet Index dataset_ ## Installation Install this plugin in the same Python environment as Datasette. ```bash datasette install datasette-nteract-data-explorer ``` ## Usage - Click "View in Data Explorer" to expand the visualization panel - Click the icons on the right side to change the visualization type. - Use the menus underneath the graphing area to configure your graph (e.g. change which columns to graph, colors to use, etc) - Use "advanced settings" mode to override the inferred column types. For example, you may want to treat a number as a "string" to be able to use it as a category. - See a [live demo](https://data-explorer.nteract.io/) of the original Nteract data-explorer component used in isolation. You can run a minimal demo after the installation step ```bash datasette -i demo/happy_planet_i… | Cameron Yick | text/markdown | https://github.com/hydrosquall/datasette-nteract-data-explorer | Apache License, Version 2.0 | https://pypi.org/project/datasette-nteract-data-explorer/ | https://pypi.org/project/datasette-nteract-data-explorer/ | {"CI": "https://github.com/hydrosquall/datasette-nteract-data-explorer/actions", "Changelog": "https://github.com/hydrosquall/datasette-nteract-data-explorer/releases", "Homepage": "https://github.com/hydrosquall/datasette-nteract-data-explorer", "Issues": "https://github.com/hydrosquall/datasette-nteract-data-explorer/issues"} | https://pypi.org/project/datasette-nteract-data-explorer/0.5.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.5.1 | 0 | ||||||
| datasette-packages | Show a list of currently installed Python packages | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-packages [](https://pypi.org/project/datasette-packages/) [](https://github.com/simonw/datasette-packages/releases) [](https://github.com/simonw/datasette-packages/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-packages/blob/main/LICENSE) Show a list of currently installed Python packages ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-packages ## Usage Visit `/-/packages` to see a list of installed Python packages. Visit `/-/packages.json` to get that back as JSON. ## Demo The output of this plugin can be seen here: - https://latest-with-plugins.datasette.io/-/packages - https://latest-with-plugins.datasette.io/-/packages.json ## With datasette-graphql if you have version 2.1 or higher of the [datasette-graphql](https://datasette.io/plugins/datasette-graphql) plugin installed you can also query the list of packages using this GraphQL query: ```graphql { packages { name version } } ``` [Demo of this query](https://latest-with-plugins.datasette.io/graphql?query=%7B%0A%20%20%20%20packages%20%7B%0A%20%20%20%20%20%20%20%20name%0A%20%20%20%20%20%20%20%20version%0A%20%20%20%20%7D%0A%7D). ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-packages python3 -mvenv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-packages | Apache License, Version 2.0 | https://pypi.org/project/datasette-packages/ | https://pypi.org/project/datasette-packages/ | {"CI": "https://github.com/simonw/datasette-packages/actions", "Changelog": "https://github.com/simonw/datasette-packages/releases", "Homepage": "https://github.com/simonw/datasette-packages", "Issues": "https://github.com/simonw/datasette-packages/issues"} | https://pypi.org/project/datasette-packages/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "datasette-graphql (>=2.1) ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-pretty-traces | Prettier formatting for ?_trace=1 traces | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-pretty-traces [](https://pypi.org/project/datasette-pretty-traces/) [](https://github.com/simonw/datasette-pretty-traces/releases) [](https://github.com/simonw/datasette-pretty-traces/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-pretty-traces/blob/main/LICENSE) Prettier formatting for `?_trace=1` traces ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-pretty-traces ## Usage Once installed, run Datasette using `--setting trace_debug 1`: datasette fixtures.db --setting trace_debug 1 Then navigate to any page and add `?_trace=` to the URL: http://localhost:8001/?_trace=1 The plugin will scroll you down the page to the visualized trace information. ## Demo You can try out the demo here: - [/?_trace=1](https://latest-with-plugins.datasette.io/?_trace=1) tracing the homepage - [/github/commits?_trace=1](https://latest-with-plugins.datasette.io/github/commits?_trace=1) tracing a table page ## Screenshot  ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-pretty-traces python3 -mvenv venv source venv/bin/activate Or if you are using `pipenv`: pipenv shell Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-pretty-traces | Apache License, Version 2.0 | https://pypi.org/project/datasette-pretty-traces/ | https://pypi.org/project/datasette-pretty-traces/ | {"CI": "https://github.com/simonw/datasette-pretty-traces/actions", "Changelog": "https://github.com/simonw/datasette-pretty-traces/releases", "Homepage": "https://github.com/simonw/datasette-pretty-traces", "Issues": "https://github.com/simonw/datasette-pretty-traces/issues"} | https://pypi.org/project/datasette-pretty-traces/0.4/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.6 | 0.4 | 0 | ||||||
| datasette-public | Make specific Datasette tables visible to the public | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-public [](https://pypi.org/project/datasette-public/) [](https://github.com/simonw/datasette-public/releases) [](https://github.com/simonw/datasette-public/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-public/blob/main/LICENSE) Make specific Datasette tables visible to the public ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-public ## Usage Any tables listed in the `_public_tables` table will be visible to the public, even if the rest of the Datasette instance does not allow anonymous access. The root user (and any user with the new `public-tables` permission) will get a new option in the table action menu allowing them to toggle a table between public and private. Installing this plugin also causes `allow-sql` permission checks to fall back to checking if the user has access to the entire database. This is to avoid users with access to a single public table being able to access data from other tables using the `?_where=` query string parameter. ## Configuration This plugin creates a new table in one of your databases called `_public_tables`. This table defaults to being created in the first database passed to Datasette. To create it in a different named database, use this plugin configuration: ```json { "plugins": { "datasette-public": { "database": "database_to_create_table_in" } } } ``` ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-public python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the test… | Simon Willison | text/markdown | https://github.com/simonw/datasette-public | Apache License, Version 2.0 | https://pypi.org/project/datasette-public/ | https://pypi.org/project/datasette-public/ | {"CI": "https://github.com/simonw/datasette-public/actions", "Changelog": "https://github.com/simonw/datasette-public/releases", "Homepage": "https://github.com/simonw/datasette-public", "Issues": "https://github.com/simonw/datasette-public/issues"} | https://pypi.org/project/datasette-public/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-query-files | Write Datasette canned queries as plain SQL files | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-query-files [](https://pypi.org/project/datasette-query-files/) [](https://github.com/eyeseast/datasette-query-files/releases) [](https://github.com/eyeseast/datasette-query-files/actions?query=workflow%3ATest) [](https://github.com/eyeseast/datasette-query-files/blob/main/LICENSE) Write Datasette canned queries as plain SQL files. ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-query-files Or using `pip` or `pipenv`: pip install datasette-query-files pipenv install datasette-query-files ## Usage This plugin will look for [canned queries](https://docs.datasette.io/en/stable/sql_queries.html#canned-queries) in the filesystem, in addition any defined in metadata. Let's say you're working in a directory called `project-directory`, with a database file called `my-project.db`. Start by creating a `queries` directory with a `my-project` directory inside it. Any SQL file inside that `my-project` folder will become a canned query that can be run on the `my-project` database. If you have a `query-name.sql` file and a `query-name.json` (or `query-name.yml`) file in the same directory, the JSON file will be used as query metadata. ``` project-directory/ my-project.db queries/ my-project/ query-name.sql # a query query-name.yml # query metadata ``` ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-query-files python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Chris Amico | text/markdown | https://github.com/eyeseast/datasette-query-files | Apache License, Version 2.0 | https://pypi.org/project/datasette-query-files/ | https://pypi.org/project/datasette-query-files/ | {"CI": "https://github.com/eyeseast/datasette-query-files/actions", "Changelog": "https://github.com/eyeseast/datasette-query-files/releases", "Homepage": "https://github.com/eyeseast/datasette-query-files", "Issues": "https://github.com/eyeseast/datasette-query-files/issues"} | https://pypi.org/project/datasette-query-files/0.1.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1.1 | 0 | ||||||
| datasette-redirect-forbidden | Redirect forbidden requests to a login page | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-redirect-forbidden [](https://pypi.org/project/datasette-redirect-forbidden/) [](https://github.com/simonw/datasette-redirect-forbidden/releases) [](https://github.com/simonw/datasette-redirect-forbidden/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-redirect-forbidden/blob/main/LICENSE) Redirect forbidden requests to a login page ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-redirect-forbidden ## Usage Add the following to your `metadata.yml` (or `metadata.json`) file to configure the plugin: ```yaml plugins: datasette-redirect-forbidden: redirect_to: /-/login ``` Any 403 forbidden pages will redirect to the specified page. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-redirect-forbidden python3 -mvenv venv source venv/bin/activate Or if you are using `pipenv`: pipenv shell Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-redirect-forbidden | Apache License, Version 2.0 | https://pypi.org/project/datasette-redirect-forbidden/ | https://pypi.org/project/datasette-redirect-forbidden/ | {"CI": "https://github.com/simonw/datasette-redirect-forbidden/actions", "Changelog": "https://github.com/simonw/datasette-redirect-forbidden/releases", "Homepage": "https://github.com/simonw/datasette-redirect-forbidden", "Issues": "https://github.com/simonw/datasette-redirect-forbidden/issues"} | https://pypi.org/project/datasette-redirect-forbidden/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.6 | 0.1 | 0 | ||||||
| datasette-render-image-tags | Turn any URLs ending in .jpg/.png/.gif into img tags with width 200 | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-render-image-tags [](https://pypi.org/project/datasette-render-image-tags/) [](https://github.com/simonw/datasette-render-image-tags/releases) [](https://github.com/simonw/datasette-render-image-tags/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-render-image-tags/blob/main/LICENSE) Turn any URLs ending in .jpg/.png/.gif into img tags with width 200 ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-render-image-tags ## Usage Once installed, any cells contaning a URL that ends with `.png` or `.jpg` or `.jpeg` or `.gif` will be rendered using an image tag, with a width of 200px. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-render-image-tags python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-render-image-tags | Apache License, Version 2.0 | https://pypi.org/project/datasette-render-image-tags/ | https://pypi.org/project/datasette-render-image-tags/ | {"CI": "https://github.com/simonw/datasette-render-image-tags/actions", "Changelog": "https://github.com/simonw/datasette-render-image-tags/releases", "Homepage": "https://github.com/simonw/datasette-render-image-tags", "Issues": "https://github.com/simonw/datasette-render-image-tags/issues"} | https://pypi.org/project/datasette-render-image-tags/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-sandstorm-support | Authentication and permissions for Datasette on Sandstorm | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-sandstorm-support [](https://pypi.org/project/datasette-sandstorm-support/) [](https://github.com/simonw/datasette-sandstorm-support/releases) [](https://github.com/simonw/datasette-sandstorm-support/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-sandstorm-support/blob/main/LICENSE) Authentication and permissions for Datasette on Sandstorm ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-sandstorm-support ## Usage This plugin is part of [datasette-sandstorm](https://github.com/ocdtrekkie/datasette-sandstorm). ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-sandstorm-support python3 -m venv venv source venv/bin/activate Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest | Simon Willison | text/markdown | https://github.com/simonw/datasette-sandstorm-support | Apache License, Version 2.0 | https://pypi.org/project/datasette-sandstorm-support/ | https://pypi.org/project/datasette-sandstorm-support/ | {"CI": "https://github.com/simonw/datasette-sandstorm-support/actions", "Changelog": "https://github.com/simonw/datasette-sandstorm-support/releases", "Homepage": "https://github.com/simonw/datasette-sandstorm-support", "Issues": "https://github.com/simonw/datasette-sandstorm-support/issues"} | https://pypi.org/project/datasette-sandstorm-support/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-scale-to-zero | Quit Datasette if it has not received traffic for a specified time period | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-scale-to-zero [](https://pypi.org/project/datasette-scale-to-zero/) [](https://github.com/simonw/datasette-scale-to-zero/releases) [](https://github.com/simonw/datasette-scale-to-zero/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-scale-to-zero/blob/main/LICENSE) Quit Datasette if it has not received traffic for a specified time period Some hosting providers such as [Fly](https://fly.io/) offer a scale to zero mechanism, where servers can shut down and will be automatically started when new traffic arrives. This plugin can be used to configure Datasette to quit X minutes (or seconds, or hours) after the last request it received. It can also cause the Datasette server to exit after a configured maximum time whether or not it is receiving traffic. ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-scale-to-zero ## Configuration This plugin will only take effect if it has been configured. Add the following to your ``metadata.json`` or ``metadata.yml`` configuration file: ```json { "plugins": { "datasette-scale-to-zero": { "duration": "10m" } } } ``` This will cause Datasette to quit if it has not received any HTTP traffic for 10 minutes. You can set this value using a suffix of `m` for minutes, `h` for hours or `s` for seconds. To cause Datasette to exit if the server has been running for longer than a specific time, use `"max-age"`: ```json { "plugins": { "datasette-scale-to-zero": { "max-age": "10h" } } } ``` This example will exit the Datasette server if it has been running for more than ten hours. You can… | Simon Willison | text/markdown | https://github.com/simonw/datasette-scale-to-zero | Apache License, Version 2.0 | https://pypi.org/project/datasette-scale-to-zero/ | https://pypi.org/project/datasette-scale-to-zero/ | {"CI": "https://github.com/simonw/datasette-scale-to-zero/actions", "Changelog": "https://github.com/simonw/datasette-scale-to-zero/releases", "Homepage": "https://github.com/simonw/datasette-scale-to-zero", "Issues": "https://github.com/simonw/datasette-scale-to-zero/issues"} | https://pypi.org/project/datasette-scale-to-zero/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.2 | 0 | ||||||
| datasette-sentry | Datasette plugin for configuring Sentry | ["License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.7", "Programming Language :: Python :: 3.8"] | # datasette-sentry [](https://pypi.org/project/datasette-sentry/) [](https://github.com/simonw/datasette-sentry/releases) [](https://github.com/simonw/datasette-sentry/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-sentry/blob/main/LICENSE) Datasette plugin for configuring Sentry for error reporting ## Installation pip install datasette-sentry ## Usage This plugin only takes effect if your `metadata.json` file contains relevant top-level plugin configuration in a `"datasette-sentry"` configuration key. You will need a Sentry DSN - see their [Getting Started instructions](https://docs.sentry.io/error-reporting/quickstart/?platform=python). Add it to `metadata.json` like this: ```json { "plugins": { "datasette-sentry": { "dsn": "https://KEY@sentry.io/PROJECTID" } } } ``` Settings in `metadata.json` are visible to anyone who visits the `/-/metadata` URL so this is a good place to take advantage of Datasette's [secret configuration values](https://datasette.readthedocs.io/en/stable/plugins.html#secret-configuration-values), in which case your configuration will look more like this: ```json { "plugins": { "datasette-sentry": { "dsn": { "$env": "SENTRY_DSN" } } } } ``` Then make a `SENTRY_DSN` environment variable available to Datasette. ## Configuration In addition to the `dsn` setting, you can also configure the Sentry [sample rate](https://docs.sentry.io/platforms/python/configuration/sampling/) by setting `sample_rate` to a floating point number between 0 and 1. For example, to capture 25% of errors you would do this: ```json { "plugins": { "datasette… | Simon Willison | text/markdown | https://github.com/simonw/datasette-sentry | Apache License, Version 2.0 | https://pypi.org/project/datasette-sentry/ | https://pypi.org/project/datasette-sentry/ | {"Homepage": "https://github.com/simonw/datasette-sentry"} | https://pypi.org/project/datasette-sentry/0.3/ | ["sentry-sdk", "datasette (>=0.62)", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | 0.3 | 0 | |||||||
| datasette-sitemap | Generate sitemap.xml for Datasette sites | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-sitemap [](https://pypi.org/project/datasette-sitemap/) [](https://github.com/simonw/datasette-sitemap/releases) [](https://github.com/simonw/datasette-sitemap/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-sitemap/blob/main/LICENSE) Generate sitemap.xml for Datasette sites ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-sitemap ## Demo This plugin is used for the sitemap on [til.simonwillison.net](https://til.simonwillison.net/): - https://til.simonwillison.net/sitemap.xml Here's [the configuration](https://github.com/simonw/til/blob/d4f67743a90a67100b46145986b2dec6f8d96583/metadata.yaml#L14-L16) used for that sitemap. ## Usage Once configured, this plugin adds a sitemap at `/sitemap.xml` with a list of URLs. This list is defined using a SQL query in `metadata.json` (or `.yml`) that looks like this: ```json { "plugins": { "datasette-sitemap": { "query": "select '/' || id as path from my_table" } } } ``` Using `metadata.yml` allows for multi-line SQL queries which can be easier to maintain: ```yaml plugins: datasette-sitemap: query: | select '/' || id as path from my_table ``` The SQL query must return a column called `path`. The values in this column must begin with a `/`. They will be used to generate a sitemap that looks like this: ```xml <?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url><loc>https://example.com/1</loc></url> <url><loc>https://example.com/2</loc></url> </urlset> ``` You can use ``UNION`` in your SQL query to combine results from multiple tables, or include liter… | Simon Willison | text/markdown | https://github.com/simonw/datasette-sitemap | Apache License, Version 2.0 | https://pypi.org/project/datasette-sitemap/ | https://pypi.org/project/datasette-sitemap/ | {"CI": "https://github.com/simonw/datasette-sitemap/actions", "Changelog": "https://github.com/simonw/datasette-sitemap/releases", "Homepage": "https://github.com/simonw/datasette-sitemap", "Issues": "https://github.com/simonw/datasette-sitemap/issues"} | https://pypi.org/project/datasette-sitemap/1.0/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "datasette-block-robots ; extra == 'test'"] | >=3.7 | 1.0 | 0 | ||||||
| datasette-socrata | Import data from Socrata into Datasette | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-socrata [](https://pypi.org/project/datasette-socrata/) [](https://github.com/simonw/datasette-socrata/releases) [](https://github.com/simonw/datasette-socrata/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-socrata/blob/main/LICENSE) Import data from Socrata into Datasette ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-socrata ## Usage Make sure you have [enabled WAL mode](https://til.simonwillison.net/sqlite/enabling-wal-mode) on your database files before using this plugin. Once installed, an interface for importing data from Socrata will become available at this URL: /-/import-socrata Users will be able to paste in a URL to a dataset on Socrata in order to initialize an import. You can also pre-fill the form by passing a `?url=` parameter, for example: /-/import-socrata?url=https://data.sfgov.org/City-Infrastructure/Street-Tree-List/tkzw-k3nq Any database that is attached to Datasette, is NOT loaded as immutable (with the `-i` option) and that has WAL mode enabled will be available for users to import data into. The `import-socrata` permission governs access. By default the `root` actor (accessible using `datasette --root` to start Datasette) is granted that permission. You can use permission plugins such as [datasette-permissions-sql](https://github.com/simonw/datasette-permissions-sql) to grant additional access to other users. ## Configuration If you only want Socrata imports to be allowed to a specific database, you can configure that using plugin configration in `metadata.yml`: ```yaml plugins: datasette-socrata: database: socrata ``` ## Development To set up this… | Simon Willison | text/markdown | https://github.com/simonw/datasette-socrata | Apache License, Version 2.0 | https://pypi.org/project/datasette-socrata/ | https://pypi.org/project/datasette-socrata/ | {"CI": "https://github.com/simonw/datasette-socrata/actions", "Changelog": "https://github.com/simonw/datasette-socrata/releases", "Homepage": "https://github.com/simonw/datasette-socrata", "Issues": "https://github.com/simonw/datasette-socrata/issues"} | https://pypi.org/project/datasette-socrata/0.3/ | ["datasette", "sqlite-utils (>=3.27)", "datasette-low-disk-space-hook", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'", "pytest-httpx ; extra == 'test'"] | >=3.7 | 0.3 | 0 | ||||||
| datasette-sqlite-fts4 | Datasette plugin exposing SQL functions from sqlite-fts4 | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-sqlite-fts4 [](https://pypi.org/project/datasette-sqlite-fts4/) [](https://github.com/simonw/datasette-sqlite-fts4/releases) [](https://github.com/simonw/datasette-sqlite-fts4/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-sqlite-fts4/blob/main/LICENSE) Datasette plugin that exposes the custom SQL functions from [sqlite-fts4](https://github.com/simonw/sqlite-fts4). [Interactive demo](https://datasette-sqlite-fts4.datasette.io/24ways-fts4?sql=select%0D%0A++++json_object%28%0D%0A++++++++"label"%2C+articles.title%2C+"href"%2C+articles.url%0D%0A++++%29+as+article%2C%0D%0A++++articles.author%2C%0D%0A++++rank_score%28matchinfo%28articles_fts%2C+"pcx"%29%29+as+score%2C%0D%0A++++rank_bm25%28matchinfo%28articles_fts%2C+"pcnalx"%29%29+as+bm25%2C%0D%0A++++json_object%28%0D%0A++++++++"pre"%2C+annotate_matchinfo%28matchinfo%28articles_fts%2C+"pcxnalyb"%29%2C+"pcxnalyb"%29%0D%0A++++%29+as+annotated_matchinfo%2C%0D%0A++++matchinfo%28articles_fts%2C+"pcxnalyb"%29+as+matchinfo%2C%0D%0A++++decode_matchinfo%28matchinfo%28articles_fts%2C+"pcxnalyb"%29%29+as+decoded_matchinfo%0D%0Afrom%0D%0A++++articles_fts+join+articles+on+articles.rowid+%3D+articles_fts.rowid%0D%0Awhere%0D%0A++++articles_fts+match+%3Asearch%0D%0Aorder+by+bm25&search=jquery+maps). Read [Exploring search relevance algorithms with SQLite](https://simonwillison.net/2019/Jan/7/exploring-search-relevance-algorithms-sqlite/) for further details on this project. ## Installation pip install datasette-sqlite-fts4 If you are deploying a database using `datasette publish` you can include this plugin using the `--install` option: datasette publish now mydb.db --install=datasette-sqlite-fts4 | Simon Willison | text/markdown | https://github.com/simonw/datasette-sqlite-fts4 | Apache License, Version 2.0 | https://pypi.org/project/datasette-sqlite-fts4/ | https://pypi.org/project/datasette-sqlite-fts4/ | {"CI": "https://github.com/simonw/datasette-sqlite-fts4/actions", "Changelog": "https://github.com/simonw/datasette-sqlite-fts4/releases", "Homepage": "https://github.com/simonw/datasette-sqlite-fts4", "Issues": "https://github.com/simonw/datasette-sqlite-fts4/issues"} | https://pypi.org/project/datasette-sqlite-fts4/0.3.2/ | ["datasette", "sqlite-fts4 (>=1.0.3)", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.3.2 | 0 | ||||||
| datasette-tiddlywiki | Run TiddlyWiki in Datasette and save Tiddlers to a SQLite database | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-tiddlywiki [](https://pypi.org/project/datasette-tiddlywiki/) [](https://github.com/simonw/datasette-tiddlywiki/releases) [](https://github.com/simonw/datasette-tiddlywiki/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-tiddlywiki/blob/main/LICENSE) Run [TiddlyWiki](https://tiddlywiki.com/) in Datasette and save Tiddlers to a SQLite database ## Installation Install this plugin in the same environment as Datasette. $ datasette install datasette-tiddlywiki ## Usage Start Datasette with a `tiddlywiki.db` database. You can create it if it does not yet exist using `--create`. You need to be signed in as the `root` user to write to the wiki, so use the `--root` option and click on the link it provides: % datasette tiddlywiki.db --create --root http://127.0.0.1:8001/-/auth-token?token=456670f1e8d01a8a33b71e17653130de17387336e29afcdfb4ab3d18261e6630 # ... Navigate to `/-/tiddlywiki` on your instance to interact with TiddlyWiki. ## Authentication and permissions By default, the wiki can be read by anyone who has permission to read the `tiddlywiki.db` database. Only the signed in `root` user can write to it. You can sign in using the `--root` option described above, or you can set a password for that user using the [datasette-auth-passwords](https://datasette.io/plugins/datasette-auth-passwords) plugin and sign in using the `/-/login` page. You can use the `edit-tiddlywiki` permission to grant edit permisions to other users, using another plugin such as [datasette-permissions-sql](https://datasette.io/plugins/datasette-permissions-sql). You can use the `view-database` permission against the `tiddlywiki` database to control who can vie… | Simon Willison | text/markdown | https://github.com/simonw/datasette-tiddlywiki | Apache License, Version 2.0 | https://pypi.org/project/datasette-tiddlywiki/ | https://pypi.org/project/datasette-tiddlywiki/ | {"CI": "https://github.com/simonw/datasette-tiddlywiki/actions", "Changelog": "https://github.com/simonw/datasette-tiddlywiki/releases", "Homepage": "https://github.com/simonw/datasette-tiddlywiki", "Issues": "https://github.com/simonw/datasette-tiddlywiki/issues"} | https://pypi.org/project/datasette-tiddlywiki/0.2/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.6 | 0.2 | 0 | ||||||
| datasette-total-page-time | Add a note to the Datasette footer measuring the total page load time | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-total-page-time [](https://pypi.org/project/datasette-total-page-time/) [](https://github.com/simonw/datasette-total-page-time/releases) [](https://github.com/simonw/datasette-total-page-time/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-total-page-time/blob/main/LICENSE) Add a note to the Datasette footer measuring the total page load time ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-total-page-time ## Usage Once this plugin is installed, a note will appear in the footer of every page showing how long the page took to generate. > Queries took 326.74ms · Page took 386.310ms ## How it works Measuring how long a page takes to load and then injecting that note into the page is tricky, because you need to finish generating the page before you know how long it took to load it! This plugin uses the [asgi_wrapper](https://docs.datasette.io/en/stable/plugin_hooks.html#asgi-wrapper-datasette) plugin hook to measure the time taken by Datasette and then inject the following JavaScript at the bottom of the response, after the closing `</html>` tag but with the correct measured value: ```html <script> let footer = document.querySelector("footer"); if (footer) { let ms = 37.224; let s = ` · Page took ${ms.toFixed(3)}ms`; footer.innerHTML += s; } </script> ``` This script is injected only on pages with the `text/html` content type - so it should not affect JSON or CSV returned by Datasette. ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd datasette-total-page-time python3 -mvenv venv s… | Simon Willison | text/markdown | https://github.com/simonw/datasette-total-page-time | Apache License, Version 2.0 | https://pypi.org/project/datasette-total-page-time/ | https://pypi.org/project/datasette-total-page-time/ | {"CI": "https://github.com/simonw/datasette-total-page-time/actions", "Changelog": "https://github.com/simonw/datasette-total-page-time/releases", "Homepage": "https://github.com/simonw/datasette-total-page-time", "Issues": "https://github.com/simonw/datasette-total-page-time/issues"} | https://pypi.org/project/datasette-total-page-time/0.1/ | ["datasette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1 | 0 | ||||||
| datasette-upload-dbs | Upload SQLite database files to Datasette | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # datasette-upload-dbs [](https://pypi.org/project/datasette-upload-dbs/) [](https://github.com/simonw/datasette-upload-dbs/releases) [](https://github.com/simonw/datasette-upload-dbs/actions?query=workflow%3ATest) [](https://github.com/simonw/datasette-upload-dbs/blob/main/LICENSE) Upload SQLite database files to Datasette ## Installation Install this plugin in the same environment as Datasette. datasette install datasette-upload-dbs ## Configuration This plugin requires you to configure a directory in which uploaded files will be stored. On startup, Datasette will automatically load any SQLite files that it finds in that directory. This means it is safe to restart your server in between file uploads. To configure the directory as `/home/datasette/uploads`, add this to a `metadata.yml` configuration file: ```yaml plugins: datasette-upload-dbs: directory: /home/datasette/uploads ``` Or if you are using `metadata.json`: ```json { "plugins": { "datasette-upload-dbs": { "directory": "/home/datasette/uploads" } } } ``` You can use `"."` for the current folder when the server starts, or `"uploads"` for a folder relative to that folder. The folder will be created on startup if it does not already exist. Then start Datasette like this: datasette -m metadata.yml ## Usage Only users with the `upload-dbs` permission will be able to upload files. The `root` user has this permission by default - other users can be granted access using permission plugins, see the [Permissions](https://docs.datasette.io/en/stable/authentication.html#permissions) documentation for details. To start Datasette as the root user, run this: datasette -m metadata.yml --roo… | Simon Willison | text/markdown | https://github.com/simonw/datasette-upload-dbs | Apache License, Version 2.0 | https://pypi.org/project/datasette-upload-dbs/ | https://pypi.org/project/datasette-upload-dbs/ | {"CI": "https://github.com/simonw/datasette-upload-dbs/actions", "Changelog": "https://github.com/simonw/datasette-upload-dbs/releases", "Homepage": "https://github.com/simonw/datasette-upload-dbs", "Issues": "https://github.com/simonw/datasette-upload-dbs/issues"} | https://pypi.org/project/datasette-upload-dbs/0.1.2/ | ["datasette", "starlette", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.7 | 0.1.2 | 0 | ||||||
| db-to-sqlite | CLI tool for exporting tables or queries from any SQL database to a SQLite file | ["Development Status :: 3 - Alpha", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7", "Topic :: Database"] | # db-to-sqlite [](https://pypi.python.org/pypi/db-to-sqlite) [](https://github.com/simonw/db-to-sqlite/releases) [](https://github.com/simonw/db-to-sqlite/actions?query=workflow%3ATest) [](https://github.com/simonw/db-to-sqlite/blob/main/LICENSE) CLI tool for exporting tables or queries from any SQL database to a SQLite file. ## Installation Install from PyPI like so: pip install db-to-sqlite If you want to use it with MySQL, you can install the extra dependency like this: pip install 'db-to-sqlite[mysql]' Installing the `mysqlclient` library on OS X can be tricky - I've found [this recipe](https://gist.github.com/simonw/90ac0afd204cd0d6d9c3135c3888d116) to work (run that before installing `db-to-sqlite`). For PostgreSQL, use this: pip install 'db-to-sqlite[postgresql]' ## Usage Usage: db-to-sqlite [OPTIONS] CONNECTION PATH Load data from any database into SQLite. PATH is a path to the SQLite file to create, e.c. /tmp/my_database.db CONNECTION is a SQLAlchemy connection string, for example: postgresql://localhost/my_database postgresql://username:passwd@localhost/my_database mysql://root@localhost/my_database mysql://username:passwd@localhost/my_database More: https://docs.sqlalchemy.org/en/13/core/engines.html#database-urls Options: --version Show the version and exit. --all Detect and copy all tables --table TEXT Specific tables to copy --skip TEXT When using --all skip these tables --redact TEXT... (table, column) pairs to redact with *** --sql TEXT Optional SQL q… | Simon Willison | text/markdown | https://github.com/simonw/db-to-sqlite | Apache License, Version 2.0 | https://pypi.org/project/db-to-sqlite/ | https://pypi.org/project/db-to-sqlite/ | {"CI": "https://travis-ci.com/simonw/db-to-sqlite", "Changelog": "https://github.com/simonw/db-to-sqlite/releases", "Documentation": "https://github.com/simonw/db-to-sqlite/blob/main/README.md", "Homepage": "https://github.com/simonw/db-to-sqlite", "Issues": "https://github.com/simonw/db-to-sqlite/issues", "Source code": "https://github.com/simonw/db-to-sqlite"} | https://pypi.org/project/db-to-sqlite/1.4/ | ["sqlalchemy", "sqlite-utils (>=2.9.1)", "click", "mysqlclient ; extra == 'mysql'", "psycopg2 ; extra == 'postgresql'", "pytest ; extra == 'test'", "pytest ; extra == 'test_mysql'", "mysqlclient ; extra == 'test_mysql'", "pytest ; extra == 'test_postgresql'", "psycopg2 ; extra == 'test_postgresql'"] | 1.4 | 0 | |||||||
| dbf-to-sqlite | CLCLI tool for converting DBF files (dBase, FoxPro etc) to SQLite | ["Development Status :: 3 - Alpha", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7", "Topic :: Database"] | # dbf-to-sqlite [](https://pypi.python.org/pypi/dbf-to-sqlite) [](https://travis-ci.com/simonw/dbf-to-sqlite) [](https://github.com/simonw/dbf-to-sqlite/blob/master/LICENSE) CLI tool for converting DBF files (dBase, FoxPro etc) to SQLite. $ dbf-to-sqlite --help Usage: dbf-to-sqlite [OPTIONS] DBF_PATHS... SQLITE_DB Convert DBF files (dBase, FoxPro etc) to SQLite https://github.com/simonw/dbf-to-sqlite Options: --version Show the version and exit. --table TEXT Table name to use (only valid for single files) -v, --verbose Show what's going on --help Show this message and exit. Example usage: $ dbf-to-sqlite *.DBF database.db This will create a new SQLite database called `database.db` containing one table for each of the `DBF` files in the current directory. Looking for DBF files to try this out on? Try downloading the [Himalayan Database](http://himalayandatabase.com/) of all expeditions that have climbed in the Nepal Himalaya. | Simon Willison | text/markdown | https://github.com/simonw/dbf-to-sqlite | Apache License, Version 2.0 | https://pypi.org/project/dbf-to-sqlite/ | https://pypi.org/project/dbf-to-sqlite/ | {"Homepage": "https://github.com/simonw/dbf-to-sqlite"} | https://pypi.org/project/dbf-to-sqlite/0.1/ | ["dbf (==0.97.11)", "click", "sqlite-utils"] | 0.1 | 0 | |||||||
| markdown-to-sqlite | CLI tool for loading markdown files into a SQLite database | ["Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7", "Topic :: Database"] | # markdown-to-sqlite [](https://pypi.python.org/pypi/markdown-to-sqlite) [](https://github.com/simonw/markdown-to-sqlite/releases) [](https://github.com/simonw/markdown-to-sqlite/actions?query=workflow%3ATest) [](https://github.com/simonw/markdown-to-sqlite/blob/main/LICENSE) CLI tool for loading markdown files into a SQLite database. YAML embedded in the markdown files will be used to populate additional columns. Usage: markdown-to-sqlite [OPTIONS] DBNAME TABLE PATHS... For example: $ markdown-to-sqlite docs.db documents file1.md file2.md ## Breaking change Prior to version 1.0 this argument order was different - markdown files were listed before the database and table. | Simon Willison | text/markdown | https://github.com/simonw/markdown-to-sqlite | Apache License, Version 2.0 | https://pypi.org/project/markdown-to-sqlite/ | https://pypi.org/project/markdown-to-sqlite/ | {"CI": "https://github.com/simonw/markdown-to-sqlite/actions", "Changelog": "https://github.com/simonw/markdown-to-sqlite/releases", "Homepage": "https://github.com/simonw/markdown-to-sqlite", "Issues": "https://github.com/simonw/markdown-to-sqlite/issues"} | https://pypi.org/project/markdown-to-sqlite/1.0/ | ["yamldown", "markdown", "sqlite-utils", "click", "pytest ; extra == 'test'"] | >=3.6 | 1.0 | 0 | ||||||
| pocket-to-sqlite | Create a SQLite database containing data from your Pocket account | ["License :: OSI Approved :: Apache Software License"] | # pocket-to-sqlite [](https://pypi.org/project/pocket-to-sqlite/) [](https://github.com/dogsheep/pocket-to-sqlite/releases) [](https://github.com/dogsheep/pocket-to-sqlite/actions?query=workflow%3ATest) [](https://github.com/dogsheep/pocket-to-sqlite/blob/main/LICENSE) Create a SQLite database containing data from your [Pocket](https://getpocket.com/) account. ## How to install $ pip install pocket-to-sqlite ## Usage You will need to first obtain a valid OAuth token for your Pocket account. You can do this by running the `auth` command and following the prompts: $ pocket-to-sqlite auth Visit this page and sign in with your Pocket account: https://getpocket.com/auth/author... Once you have signed in there, hit <enter> to continue Authentication tokens written to auth.json Now you can fetch all of your items from Pocket like this: $ pocket-to-sqlite fetch pocket.db The first time you run this command it will fetch all of your items, and display a progress bar while it does it. On subsequent runs it will only fetch new items. You can force it to fetch everything from the beginning again using `--all`. Use `--silent` to disable the progress bar. ## Using with Datasette The SQLite database produced by this tool is designed to be browsed using [Datasette](https://datasette.readthedocs.io/). Use the [datasette-render-timestamps](https://github.com/simonw/datasette-render-timestamps) plugin to improve the display of the timestamp values. | Simon Willison | text/markdown | https://github.com/dogsheep/pocket-to-sqlite | Apache License, Version 2.0 | https://pypi.org/project/pocket-to-sqlite/ | https://pypi.org/project/pocket-to-sqlite/ | {"CI": "https://github.com/dogsheep/pocket-to-sqlite/actions", "Changelog": "https://github.com/dogsheep/pocket-to-sqlite/releases", "Homepage": "https://github.com/dogsheep/pocket-to-sqlite", "Issues": "https://github.com/dogsheep/pocket-to-sqlite/issues"} | https://pypi.org/project/pocket-to-sqlite/0.2.2/ | ["sqlite-utils (>=2.4.4)", "click", "requests", "pytest ; extra == 'test'"] | 0.2.2 | 0 | |||||||
| sqlite-colorbrewer | A custom function to use ColorBrewer scales in SQLite queries | ["Framework :: Datasette", "License :: OSI Approved :: Apache Software License"] | # sqlite-colorbrewer [](https://pypi.org/project/sqlite-colorbrewer/) [](https://github.com/eyeseast/sqlite-colorbrewer/releases) [](https://github.com/eyeseast/sqlite-colorbrewer/actions?query=workflow%3ATest) [](https://github.com/eyeseast/sqlite-colorbrewer/blob/main/LICENSE) A custom function to use [ColorBrewer](https://colorbrewer2.org/) scales in SQLite queries. Colors are exported from [here](https://colorbrewer2.org/export/colorbrewer.json). ## Installation To install as a Python library and use with the [standard SQLite3 module](https://docs.python.org/3/library/sqlite3.html): pip install sqlite-colorbrewer To install this plugin in the same environment as Datasette. datasette install sqlite-colorbrewer ## Usage If you're using this library with Datasette, it will be automatically registered as a plugin and available for use in SQL queries, like so: ```sql SELECT colorbrewer('Blues', 9, 0); ``` That will return a single value: `"rgb(247,251,255)"` To use with a SQLite connection outside of Datasette, use the `register` function: ```python >>> import sqlite3 >>> import sqlite_colorbrewer >>> conn = sqlite3.connect(':memory') >>> sqlite_colorbrewer.register(conn) >>> cursor = conn.execute("SELECT colorbrewer('Blues', 9, 0);") >>> result = next(cursor) >>> print(result) rgb(247,251,255) ``` ## Development To set up this plugin locally, first checkout the code. Then create a new virtual environment: cd sqlite-colorbrewer python3 -mvenv venv source venv/bin/activate Or if you are using `pipenv`: pipenv shell Now install the dependencies and test dependencies: pip install -e '.[test]' To run the tests: pytest To build `sqlite_col… | Chris Amico | text/markdown | https://github.com/eyeseast/sqlite-colorbrewer | Apache License, Version 2.0 | https://pypi.org/project/sqlite-colorbrewer/ | https://pypi.org/project/sqlite-colorbrewer/ | {"CI": "https://github.com/eyeseast/sqlite-colorbrewer/actions", "Changelog": "https://github.com/eyeseast/sqlite-colorbrewer/releases", "Homepage": "https://github.com/eyeseast/sqlite-colorbrewer", "Issues": "https://github.com/eyeseast/sqlite-colorbrewer/issues"} | https://pypi.org/project/sqlite-colorbrewer/0.2/ | ["datasette ; extra == 'test'", "pytest ; extra == 'test'", "pytest-asyncio ; extra == 'test'"] | >=3.6 | 0.2 | 0 | ||||||
| sqlite-diffable | Tools for dumping/loading a SQLite database to diffable directory structure | ["Development Status :: 3 - Alpha", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7", "Topic :: Database"] | # sqlite-diffable [](https://pypi.org/project/sqlite-diffable/) [](https://github.com/simonw/sqlite-diffable/releases) [](https://github.com/simonw/sqlite-diffable/blob/main/LICENSE) Tools for dumping/loading a SQLite database to diffable directory structure ## Installation pip install sqlite-diffable ## Demo The repository at [simonw/simonwillisonblog-backup](https://github.com/simonw/simonwillisonblog-backup) contains a backup of the database on my blog, https://simonwillison.net/ - created using this tool. ## Dumping a database Given a SQLite database called `fixtures.db` containing a table `facetable`, the following will dump out that table to the `dump/` directory: sqlite-diffable dump fixtures.db dump/ facetable To dump out every table in that database, use `--all`: sqlite-diffable dump fixtures.db dump/ --all ## Loading a database To load a previously dumped database, run the following: sqlite-diffable load restored.db dump/ This will show an error if any of the tables that are being restored already exist in the database file. You can replace those tables (dropping them before restoring them) using the `--replace` option: sqlite-diffable load restored.db dump/ --replace ## Converting to JSON objects Table rows are stored in the `.ndjson` files as newline-delimited JSON arrays, like this: ``` ["a", "a", "a-a", 63, null, 0.7364712141640124, "$null"] ["a", "b", "a-b", 51, null, 0.6020187290499803, "$null"] ``` Sometimes it can be more convenient to work with a list of JSON objects. The `sqlite-diffable objects` command can read a `.ndjson` file and its accompanying `.metadata.json` file and output JSON objects to standard output: sqlite-diffable objects fixtures.db dump/sortable.ndjson The output of that command looks somethi… | Simon Willison | text/markdown | https://github.com/simonw/sqlite-diffable | Apache License, Version 2.0 | https://pypi.org/project/sqlite-diffable/ | https://pypi.org/project/sqlite-diffable/ | {"CI": "https://github.com/simonw/sqlite-diffable/actions", "Changelog": "https://github.com/simonw/sqlite-diffable/releases", "Homepage": "https://github.com/simonw/sqlite-diffable", "Issues": "https://github.com/simonw/sqlite-diffable/issues"} | https://pypi.org/project/sqlite-diffable/0.5/ | ["click", "sqlite-utils", "pytest ; extra == 'test'", "black ; extra == 'test'"] | 0.5 | 0 | |||||||
| sqlite-utils | CLI tool and Python utility functions for manipulating SQLite databases | ["Development Status :: 5 - Production/Stable", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.10", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7", "Programming Language :: Python :: 3.8", "Programming Language :: Python :: 3.9", "Topic :: Database"] | # sqlite-utils [](https://pypi.org/project/sqlite-utils/) [](https://sqlite-utils.datasette.io/en/stable/changelog.html) [](https://pypi.org/project/sqlite-utils/) [](https://github.com/simonw/sqlite-utils/actions?query=workflow%3ATest) [](http://sqlite-utils.datasette.io/en/stable/?badge=stable) [](https://codecov.io/gh/simonw/sqlite-utils) [](https://github.com/simonw/sqlite-utils/blob/main/LICENSE) [](https://discord.gg/Ass7bCAMDw) Python CLI utility and library for manipulating SQLite databases. ## Some feature highlights - [Pipe JSON](https://sqlite-utils.datasette.io/en/stable/cli.html#inserting-json-data) (or [CSV or TSV](https://sqlite-utils.datasette.io/en/stable/cli.html#inserting-csv-or-tsv-data)) directly into a new SQLite database file, automatically creating a table with the appropriate schema - [Run in-memory SQL queries](https://sqlite-utils.datasette.io/en/stable/cli.html#querying-data-directly-using-an-in-memory-database), including joins, directly against data in CSV, TSV or JSON files and view the results - [Configure SQLite full-text search](https://sqlite-utils.datasette.io/en/stable/cli.html#configuring-full-text-search) against your database tables and run search queries against them, ordered by relevance - Run [transformations against your tables](https://sqlite-utils.datasette.io/en/stable/cli.html#transforming-tables) to make schema changes t… | Simon Willison | text/markdown | https://github.com/simonw/sqlite-utils | Apache License, Version 2.0 | https://pypi.org/project/sqlite-utils/ | https://pypi.org/project/sqlite-utils/ | {"CI": "https://github.com/simonw/sqlite-utils/actions", "Changelog": "https://sqlite-utils.datasette.io/en/stable/changelog.html", "Documentation": "https://sqlite-utils.datasette.io/en/stable/", "Homepage": "https://github.com/simonw/sqlite-utils", "Issues": "https://github.com/simonw/sqlite-utils/issues", "Source code": "https://github.com/simonw/sqlite-utils"} | https://pypi.org/project/sqlite-utils/3.30/ | ["sqlite-fts4", "click", "click-default-group-wheel", "tabulate", "python-dateutil", "furo ; extra == 'docs'", "sphinx-autobuild ; extra == 'docs'", "codespell ; extra == 'docs'", "sphinx-copybutton ; extra == 'docs'", "beanbag-docutils (>=2.0) ; extra == 'docs'", "flake8 ; extra == 'flake8'", "mypy ; extra == 'mypy'", "types-click ; extra == 'mypy'", "types-tabulate ; extra == 'mypy'", "types-python-dateutil ; extra == 'mypy'", "data-science-types ; extra == 'mypy'", "pytest ; extra == 'test'", "black ; extra == 'test'", "hypothesis ; extra == 'test'", "cogapp ; extra == 'test'"] | >=3.6 | 3.30 | 0 | ||||||
| yaml-to-sqlite | Utility for converting YAML files to SQLite | ["Development Status :: 3 - Alpha", "Intended Audience :: Developers", "Intended Audience :: End Users/Desktop", "Intended Audience :: Science/Research", "License :: OSI Approved :: Apache Software License", "Programming Language :: Python :: 3.6", "Programming Language :: Python :: 3.7"] | # yaml-to-sqlite [](https://pypi.org/project/yaml-to-sqlite/) [](https://github.com/simonw/yaml-to-sqlite/releases) [](https://github.com/simonw/yaml-to-sqlite/actions?query=workflow%3ATest) [](https://github.com/simonw/yaml-to-sqlite/blob/main/LICENSE) Load the contents of a YAML file into a SQLite database table. ``` $ yaml-to-sqlite --help Usage: yaml-to-sqlite [OPTIONS] DB_PATH TABLE YAML_FILE Convert YAML files to SQLite Options: --version Show the version and exit. --pk TEXT Column to use as a primary key --single-column TEXT If YAML file is a list of values, populate this column --help Show this message and exit. ``` ## Usage Given a `news.yml` file containing the following: ```yaml - date: 2021-06-05 body: |- [Datasette 0.57](https://docs.datasette.io/en/stable/changelog.html#v0-57) is out with an important security patch. - date: 2021-05-10 body: |- [Django SQL Dashboard](https://simonwillison.net/2021/May/10/django-sql-dashboard/) is a new tool that brings a useful authenticated subset of Datasette to Django projects that are built on top of PostgreSQL. ``` Running this command: ```bash $ yaml-to-sqlite news.db stories news.yml ``` Will create a database file with this schema: ```bash $ sqlite-utils schema news.db CREATE TABLE [stories] ( [date] TEXT, [body] TEXT ); ``` The `--pk` option can be used to set a column as the primary key for the table: ```bash $ yaml-to-sqlite news.db stories news.yml --pk date $ sqlite-utils schema news.db CREATE TABLE [stories] ( [date] TEXT PRIMARY KEY, [body] TEXT ); ``` ## Single column YAML lists The `--single-column` option can be used when the YAML file is a list of values, for … | Simon Willison | text/markdown | https://github.com/simonw/yaml-to-sqlite | Apache License, Version 2.0 | https://pypi.org/project/yaml-to-sqlite/ | https://pypi.org/project/yaml-to-sqlite/ | {"Homepage": "https://github.com/simonw/yaml-to-sqlite"} | https://pypi.org/project/yaml-to-sqlite/1.0/ | ["click", "PyYAML", "sqlite-utils (>=3.9.1)", "pytest ; extra == 'test'"] | 1.0 | 0 |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [pypi_packages] ( [name] TEXT PRIMARY KEY, [summary] TEXT, [classifiers] TEXT, [description] TEXT, [author] TEXT, [author_email] TEXT, [description_content_type] TEXT, [home_page] TEXT, [keywords] TEXT, [license] TEXT, [maintainer] TEXT, [maintainer_email] TEXT, [package_url] TEXT, [platform] TEXT, [project_url] TEXT, [project_urls] TEXT, [release_url] TEXT, [requires_dist] TEXT, [requires_python] TEXT, [version] TEXT, [yanked] INTEGER, [yanked_reason] TEXT );